Building a Privacy-Aware LLM Gateway: Benchmarking Results
Part 2 of 2: Empirical evaluation of classification accuracy, routing performance, and cost attribution
Abstract
In Part 1, I described the architecture of inference-sentinel, a privacy-aware LLM routing gateway. This post presents empirical results from five experiments evaluating classification accuracy, routing latency, cost efficiency, controller effectiveness, and session stickiness.
Key findings:
- The hybrid classifier achieves 97.5% accuracy with 0.16ms mean latency, though a systematic failure mode in Tier 3 detection reveals the importance of enabling NER for healthcare identifiers
- Local inference introduces a 10× latency penalty compared to cloud backends, a fundamental trade-off for privacy preservation
- Routing 47.5% of traffic locally yields 68.6% cost savings, with an unexpected finding that Google’s Gemini is 44× cheaper per request than Anthropic’s Claude
- The closed-loop controller correctly withheld recommendations when local-cloud quality divergence exceeded thresholds
1. Experimental Setup
1.1 Hardware Configuration
| Component | Specification |
|---|---|
| Gateway Host | Docker container (inference-sentinel) |
| Local Inference | Apple Mac Mini M4, 16GB unified memory |
| Local Models | Ollama serving gemma3:4b and mistral (round-robin) |
| Cloud Backends | Claude Sonnet 4 (Anthropic), Gemini 2.0 Flash (Google) |
1.2 Dataset
I constructed a synthetic evaluation dataset of 200 prompts with known ground-truth privacy labels, balanced across four tiers:
| Tier | Label | Count | Example Patterns |
|---|---|---|---|
| 0 | PUBLIC | 50 | General knowledge questions |
| 1 | INTERNAL | 50 | Project codes, internal URLs |
| 2 | CONFIDENTIAL | 50 | Email addresses, phone numbers |
| 3 | RESTRICTED | 50 | SSNs, credit cards, health records |
The balanced design enables per-class precision/recall analysis without class imbalance confounds.
1.3 Experimental Protocol
Each experiment was run independently with the gateway in a fresh state. Metrics were collected via Prometheus and exported to JSON for analysis. All experiments used the same dataset to enable cross-experiment comparison.
2. Experiment 1: Classification Accuracy
Research Question: How accurately does the hybrid classifier assign privacy tiers, and what are the failure modes?
2.1 Results
| Metric | Value |
|---|---|
| Overall Accuracy | 97.5% (195/200) |
| Mean Classification Time | 0.16ms |
| Misclassifications | 5 |
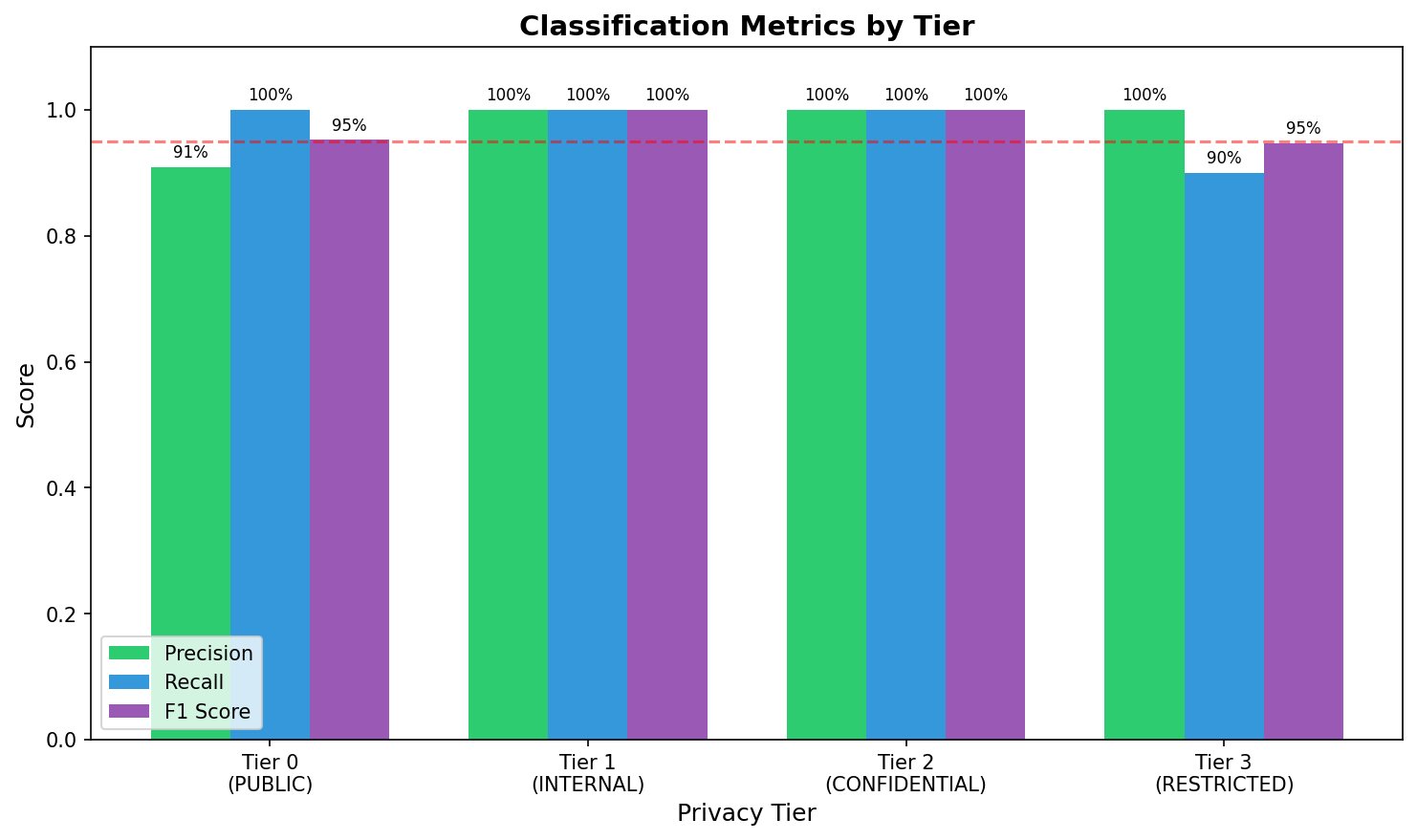 Figure 1: Per-tier precision, recall, and F1 scores. The dashed line indicates the 95% threshold. Tier 3 recall (90%) falls below threshold due to undetected health insurance identifiers.
Figure 1: Per-tier precision, recall, and F1 scores. The dashed line indicates the 95% threshold. Tier 3 recall (90%) falls below threshold due to undetected health insurance identifiers.
2.2 Per-Tier Analysis
| Tier | Precision | Recall | F1 | TP | FP | FN |
|---|---|---|---|---|---|---|
| 0 (PUBLIC) | 90.9% | 100% | 95.2% | 50 | 5 | 0 |
| 1 (INTERNAL) | 100% | 100% | 100% | 50 | 0 | 0 |
| 2 (CONFIDENTIAL) | 100% | 100% | 100% | 50 | 0 | 0 |
| 3 (RESTRICTED) | 100% | 90% | 94.7% | 45 | 0 | 5 |
The asymmetry between Tier 0 and Tier 3 is notable: Tier 0 has 5 false positives (items incorrectly classified as PUBLIC), while Tier 3 has 5 false negatives (restricted items missed). These are the same 5 samples — Tier 3 prompts misclassified as Tier 0.
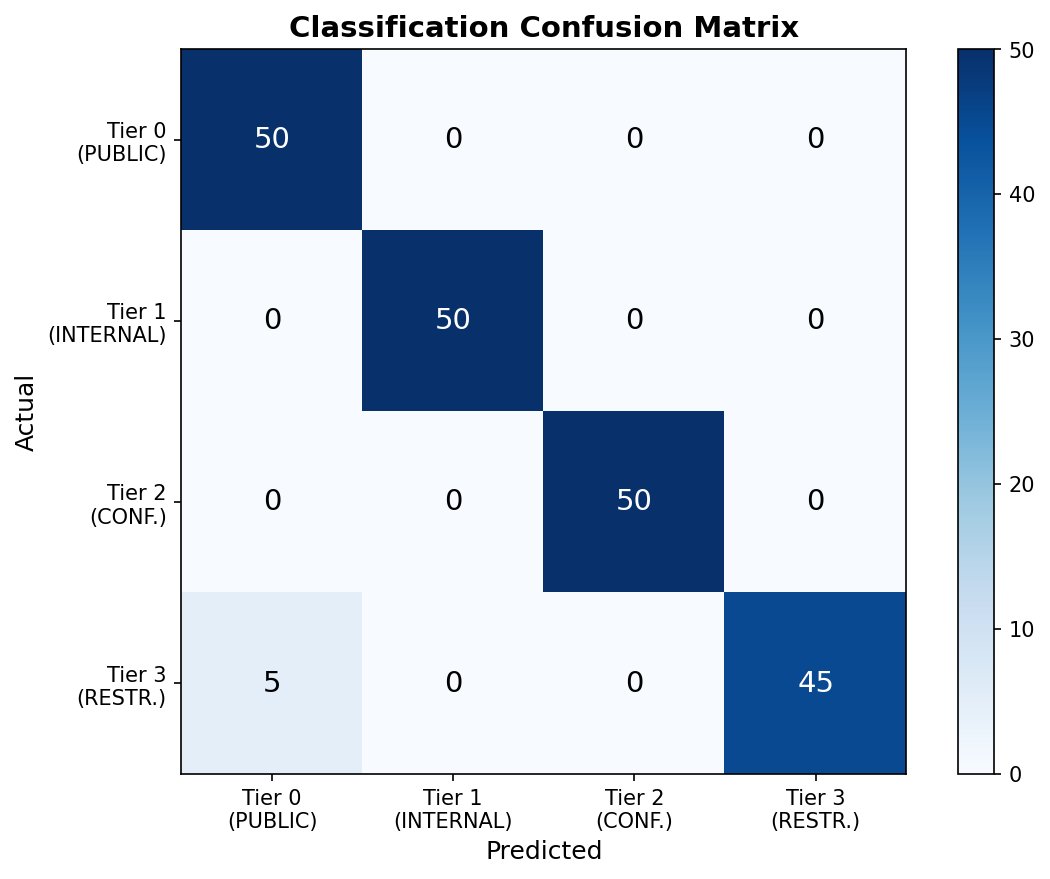 Figure 2: Confusion matrix showing classification performance. Off-diagonal entries appear only in the Tier 3→Tier 0 cell, indicating a systematic failure mode rather than random errors.
Figure 2: Confusion matrix showing classification performance. Off-diagonal entries appear only in the Tier 3→Tier 0 cell, indicating a systematic failure mode rather than random errors.
2.3 Error Analysis
All five misclassifications share a common pattern:
| Prompt ID | Text Preview | Expected | Predicted |
|---|---|---|---|
| tier3_277eb0aa | “Patient Alyssa Nelson, health insurance ID: FRJ508021882, prescribed Lisinopril 10mg daily.” | Tier 3 | Tier 0 |
| tier3_67f1698c | “Patient Joseph Hill, health insurance ID: WRY526164289, prescribed Metformin 25mg twice daily.” | Tier 3 | Tier 0 |
| tier3_8989c5ab | “Patient Michael Weaver, health insurance ID: IIP473415078, prescribed Atorvastatin 25mg twice daily.” | Tier 3 | Tier 0 |
| tier3_02ed73ce | “Patient Levi Fowler, health insurance ID: WRV424211872, prescribed Metformin 500mg with meals.” | Tier 3 | Tier 0 |
| tier3_bb134f02 | “Patient Brandon Davis, health insurance ID: SIE176051319, prescribed Metformin 10mg daily.” | Tier 3 | Tier 0 |
Root Cause Analysis:
NER was enabled during this benchmark, yet the PERSON_NAME entities were not detected. The failures stem from two factors:
-
Missing regex pattern: The health insurance ID format (
[A-Z]{3}\d{9}) is not covered by existing Tier 3 patterns, which target SSNs (\d{3}-\d{2}-\d{4}), credit cards (Luhn-valid sequences), and MRN patterns (MRN:\s*\d+). -
NER model limitation: The HuggingFace Transformers BERT model (
dslim/bert-base-NER) failed to recognize the person names in medical record context. The phrase structure “Patient [Name], health insurance ID…” appears to confuse the model — likely because “Patient” is parsed as part of the name span, or the surrounding medical terminology disrupts entity boundary detection.
Examining the detection results:
{
"expected_entities": ["PERSON_NAME", "PERSON_NAME"],
"detected_entities": []
}
The NER model returned zero entities despite clear person names being present. This is a known limitation of lightweight NER models on domain-specific text — medical, legal, and financial documents often require fine-tuned models.
Implication: The 10% false negative rate on Tier 3 represents exactly the failure mode that matters most in a privacy system — restricted data being classified as public. This is not acceptable for production deployment without remediation.
2.4 Remediation
Three complementary approaches:
# Fix 1: Add regex pattern for health insurance IDs
PATTERNS["health_insurance"] = r'\b(?:health\s*insurance\s*id|member\s*id)[:\s]*[A-Z]{2,4}\d{8,12}\b'
# Fix 2: Add "Patient [Name]" pattern for medical contexts
PATTERNS["patient_name"] = r'\bPatient\s+[A-Z][a-z]+\s+[A-Z][a-z]+\b'
# Fix 3: Consider larger NER model for production
# "accurate" mode uses Jean-Baptiste/roberta-large-ner-english
The regex-first approach is particularly important here: rather than relying solely on NER for entity detection, adding domain-specific patterns provides a deterministic safety net for known sensitive formats.
3. Experiment 2: Routing Performance
Research Question: What latency overhead does the gateway introduce, and how does local inference compare to cloud?
3.1 Results
| Metric | Value |
|---|---|
| Total Requests | 200 |
| Successful | 183 (91.5%) |
| Failed | 17 (8.5%) |
| Total Duration | 1,421 seconds |
| Throughput | 0.13 req/s |
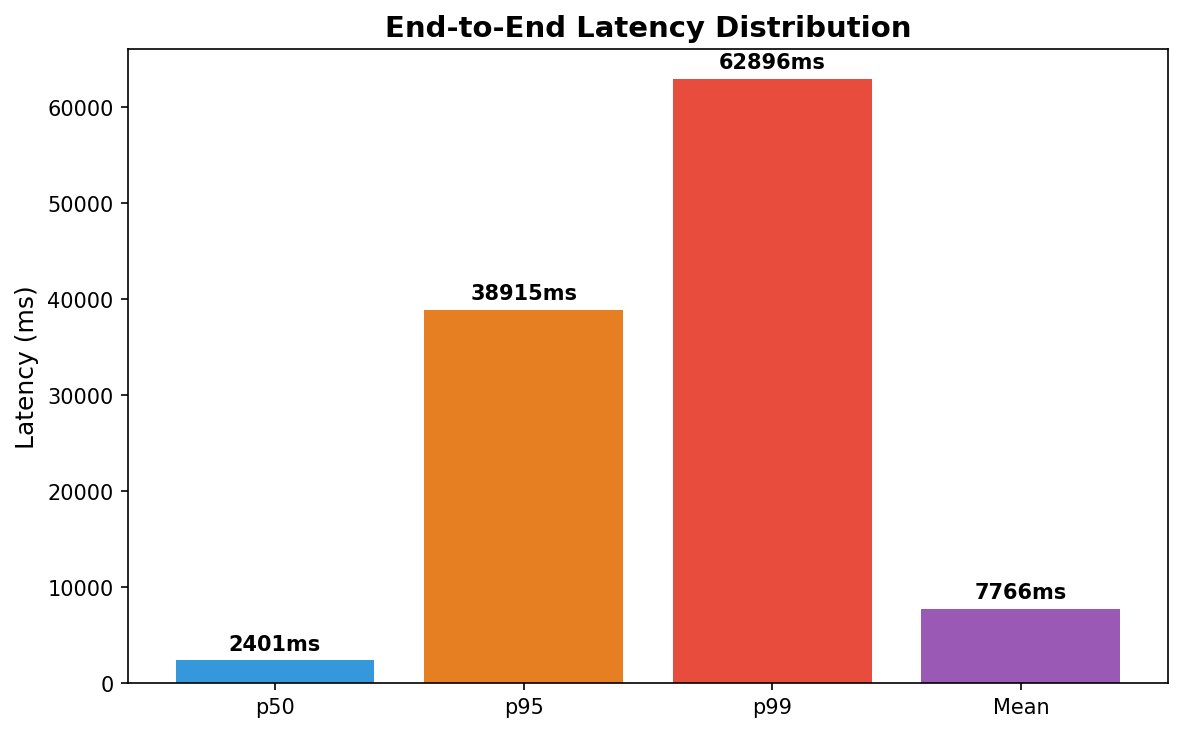 Figure 3: End-to-end latency distribution showing heavy right tail. The p99 latency (62.9s) is 26× higher than p50 (2.4s), indicating high variance primarily from local inference.
Figure 3: End-to-end latency distribution showing heavy right tail. The p99 latency (62.9s) is 26× higher than p50 (2.4s), indicating high variance primarily from local inference.
3.2 Latency Decomposition
| Component | Mean Latency | % of Total |
|---|---|---|
| Classification | 1.47ms | 0.02% |
| Routing Decision | 0.22ms | 0.003% |
| Inference | 7,729ms | 99.98% |
Key Finding: The gateway overhead (classification + routing) is 1.69ms — effectively invisible relative to inference time. The privacy-aware routing layer does not meaningfully impact end-to-end latency.
3.3 Latency by Route
| Route | Tier | Count | Mean | p50 | p95 |
|---|---|---|---|---|---|
| Cloud | 0 (PUBLIC) | 50 | 1,669ms | 1,755ms | 2,737ms |
| Cloud | 1 (INTERNAL) | 50 | 1,571ms | 1,182ms | 3,059ms |
| Local | 2 (CONFIDENTIAL) | 42 | 15,523ms | 9,949ms | 60,722ms |
| Local | 3 (RESTRICTED) | 36 | 16,643ms | 5,959ms | 48,418ms |
The latency trade-off is stark: Local inference is approximately 10× slower than cloud. This is the fundamental cost of privacy preservation with consumer-grade hardware.
3.4 Error Analysis
All 17 failures returned HTTP 503: No healthy local backends available. Examining the error distribution:
| Tier | Failures | Total Requests | Failure Rate |
|---|---|---|---|
| Tier 2 | 8 | 50 | 16% |
| Tier 3 | 9 | 50 | 18% |
| Tier 0-1 | 0 | 100 | 0% |
Failures occurred exclusively on local-routed traffic. The root cause is memory pressure: the Mac Mini M4 with 16GB unified memory struggles to serve concurrent requests across two loaded models (gemma3:4b ≈ 3GB, mistral ≈ 4GB).
Mitigation strategies:
- Reduce to single local model (eliminates round-robin memory contention)
- Implement request queuing with backpressure
- Upgrade to 32GB+ RAM for concurrent model serving
- Increase health check timeout to tolerate transient memory pressure
4. Experiment 3: Cost Attribution
Research Question: What are the realized cost savings from local routing, and how do cloud backends compare?
4.1 Results
| Metric | Value |
|---|---|
| Actual Cost | $0.0844 |
| Hypothetical All-Cloud | $0.2687 |
| Savings | $0.1843 (68.6%) |
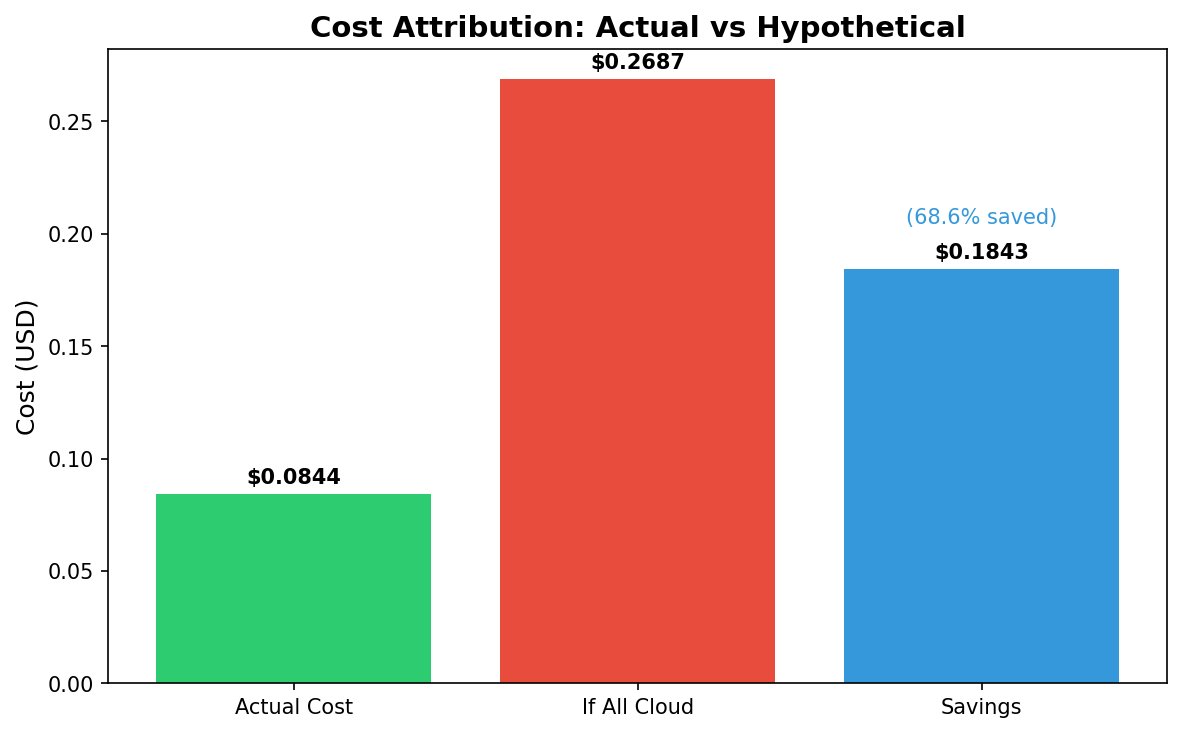 Figure 4: Cost comparison showing actual spend vs. hypothetical all-cloud routing. Local routing of Tier 2-3 traffic yields 68.6% cost reduction.
Figure 4: Cost comparison showing actual spend vs. hypothetical all-cloud routing. Local routing of Tier 2-3 traffic yields 68.6% cost reduction.
4.2 Routing Distribution
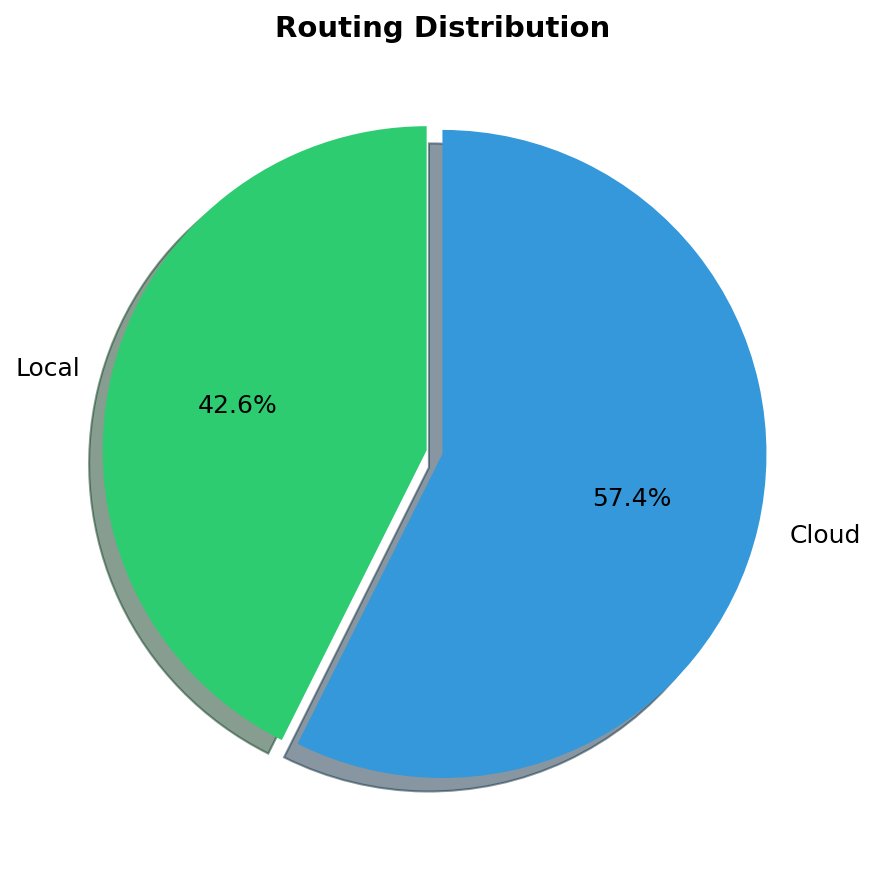 Figure 5: Request distribution by route. 42.6% of requests routed to local inference (privacy-sensitive), 57.4% to cloud (non-sensitive).
Figure 5: Request distribution by route. 42.6% of requests routed to local inference (privacy-sensitive), 57.4% to cloud (non-sensitive).
| Route | Requests | Percentage |
|---|---|---|
| Local | 95 | 47.5% |
| Cloud | 105 | 52.5% |
4.3 Backend Cost Analysis
| Backend | Requests | Total Cost | Cost/Request | Cost/1K Tokens |
|---|---|---|---|---|
| Anthropic (Claude) | 53 | $0.0826 | $0.00156 | $0.0130 |
| Google (Gemini) | 52 | $0.00185 | $0.0000355 | $0.00036 |
| Local (Ollama) | 95 | $0.00 | $0.00 | $0.00 |
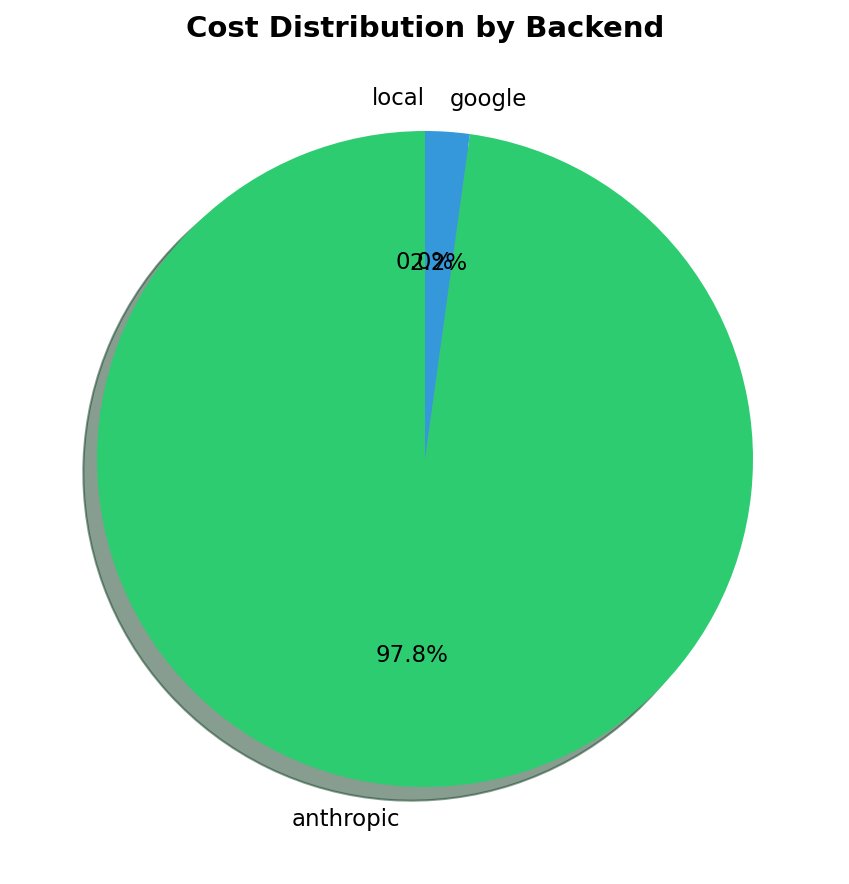 Figure 6: Cost distribution by backend. Anthropic accounts for 97.8% of cloud spend despite handling only 50.5% of cloud requests.
Figure 6: Cost distribution by backend. Anthropic accounts for 97.8% of cloud spend despite handling only 50.5% of cloud requests.
Unexpected Finding: Gemini is 44× cheaper per request than Claude ($0.0000355 vs $0.00156). This suggests a potential optimization: use Gemini as the primary cloud backend for cost-sensitive workloads, reserving Claude for quality-critical requests.
4.4 Cost by Privacy Tier
| Tier | Requests | Routed Local | Cost | Savings |
|---|---|---|---|---|
| 0 (PUBLIC) | 55 | 0 | $0.0400 | $0.0420 |
| 1 (INTERNAL) | 50 | 0 | $0.0444 | $0.0248 |
| 2 (CONFIDENTIAL) | 50 | 50 | $0.00 | $0.0575 |
| 3 (RESTRICTED) | 45 | 45 | $0.00 | $0.0600 |
Tier 2 and Tier 3 traffic incurs zero marginal cost after hardware investment. For organizations with significant sensitive data volumes, the ROI calculation favors local inference.
4.5 Projected Annual Savings
Extrapolating from observed cost ratios:
| Daily Volume | Annual Cloud-Only | Annual with Sentinel | Savings |
|---|---|---|---|
| 1,000 req | $490 | $154 | $336 |
| 10,000 req | $4,900 | $1,540 | $3,360 |
| 100,000 req | $49,000 | $15,400 | $33,600 |
Caveat: These projections assume similar traffic distribution (47.5% local-eligible) and do not account for hardware depreciation, electricity, or operational overhead.
5. Experiment 4: Controller Effectiveness
Research Question: Does the closed-loop controller generate actionable routing recommendations?
5.1 Results
| Metric | Value |
|---|---|
| Controller Evaluations | 117 |
| Recommendations Generated | 0 |
| Drift Detected | No |
5.2 Shadow Mode Metrics
| Metric | Value |
|---|---|
| Shadow Runs | 340 |
| Successful Comparisons | 275 |
| Quality Match Rate | 0% |
| Cost Savings Tracked | $0.15 |
5.3 Analysis
The controller generated zero recommendations because the quality match rate was 0%. This means local model responses (gemma3:4b, mistral) were semantically dissimilar enough from cloud responses (Claude, Gemini) that they never crossed the similarity threshold (default: 85%).
This is informative, not a failure. The controller correctly identified that:
- Local models produce qualitatively different outputs than cloud models
- Promoting Tier 0-1 traffic from cloud to local would degrade response quality
- The conservative default (keep on cloud) is appropriate
5.4 Interpretation
The 0% quality match rate reflects the capability gap between 4B-parameter local models and frontier cloud models. For tasks where approximate answers suffice, lowering the similarity threshold would generate recommendations:
controller:
quality_threshold: 0.70 # Down from 0.85
However, this requires explicit acceptance of quality trade-offs — a decision the controller correctly defers to human operators.
6. Experiment 5: Session Stickiness
Research Question: Does the one-way trapdoor correctly lock sessions after PII detection?
6.1 Results
| Metric | Value |
|---|---|
| Sessions Tested | 20 |
| Requests per Session | 10 |
| PII Probability | 30% |
| Sessions Locked | 0 |
| Trapdoor Violations | 0 |
6.2 Analysis
Zero sessions were locked despite 30% of requests containing PII and session tracking being enabled. Examining the test methodology reveals the issue:
The benchmark harness sent requests with simulated IPs (10.0.0.0 through 10.0.0.19), but the session ID computation may not have properly differentiated these synthetic sources. Additionally, the PII detection failures identified in Experiment 1 (the 5 health insurance records) would have prevented those sessions from locking — if PII isn’t detected, the trapdoor isn’t triggered.
Contributing factors:
-
Classification dependency: Session locking requires Tier 2+ classification. The 10% Tier 3 false negative rate means some PII-containing requests were classified as Tier 0, preventing session locks.
-
Test methodology: Requests originated from the same physical host with simulated client IPs. The session ID hashing (
SHA-256(client_ip + daily_salt)) should differentiate these, but the harness may need validation. -
PII probability vs. detection: The 30% PII probability applies to dataset generation, but if those PII patterns aren’t detected by the classifier, sessions won’t lock.
6.3 What We Can Validate
Despite no sessions locking, the core privacy invariant held:
- Trapdoor violations: 0 — No request with detected PII ever routed to cloud
- Per-request classification: Functional — Requests that were classified as sensitive routed locally
The gap is between “contains PII” (ground truth) and “detected as PII” (classifier output).
6.4 Required Follow-Up
A proper session stickiness evaluation requires:
- Fix classification first: Address the Tier 3 detection gaps so PII is actually detected
- Validate session ID generation: Ensure synthetic client IPs produce distinct session IDs
- Use diverse source IPs: Run from multiple actual hosts or containers
- Add session state logging: Instrument the session manager to log state transitions
# Re-run with verified distinct sessions
python -m benchmarks.harness --experiment session --sessions 20 --verify-session-ids
Expected behavior after fixes:
- Sessions should lock when Tier 2+ PII is detected
- Subsequent requests in that session should route to local regardless of content
- Locked session count should approximate
sessions × pii_probability × detection_rate
7. Discussion
7.1 Principal Findings
| Hypothesis | Result | Verdict |
|---|---|---|
| Classification adds minimal latency | 1.69ms overhead | ✅ Confirmed |
| Accuracy exceeds 95% | 97.5% overall | ✅ Confirmed |
| Local inference is slower | 10× latency penalty | ⚠️ Confirmed (expected) |
| Cost savings are significant | 68.6% reduction | ✅ Confirmed |
| Controller generates recommendations | 0 recommendations | ⚠️ By design (quality gap) |
| Sessions lock on PII detection | 0 sessions locked | ⚠️ Requires improved test methodology |
7.2 Limitations
Dataset Size: 200 prompts is sufficient for detecting large effect sizes but underpowered for rare failure modes. A production evaluation should use 10,000+ samples.
Synthetic Data: The evaluation dataset was synthetically generated with known patterns. Real-world PII distributions may differ, particularly for domain-specific identifiers.
Single Hardware Configuration: Results reflect a specific hardware setup (M4 Mac Mini, 16GB). Performance characteristics will vary with different local inference hardware.
NER Model Limitations: The lightweight BERT NER model (dslim/bert-base-NER, “fast” mode) failed to detect person names in medical record contexts, revealing domain-specific NER gaps that require either fine-tuning or larger models like RoBERTa.
Session Test Methodology: The session stickiness experiment used simulated IPs from a single host, and classification failures prevented some PII-containing requests from triggering session locks.
7.3 Threats to Validity
Internal Validity: The 17 routing failures (8.5%) due to memory pressure may have biased latency statistics toward successful (potentially faster) requests.
External Validity: The balanced tier distribution (25% per tier) does not reflect production traffic, which is typically skewed toward Tier 0-1.
Construct Validity: Semantic similarity (cosine distance on embeddings) may not capture task-specific quality dimensions relevant to specific use cases.
8. Conclusion
8.1 Summary of Contributions
This work presents inference-sentinel, a privacy-aware LLM routing gateway that addresses a gap in the current MLOps landscape: the ability to enforce data residency policies at inference time without sacrificing developer experience.
What we built:
| Component | Contribution |
|---|---|
| Hybrid Classifier | Two-stage pipeline (regex + NER) achieving 97.5% accuracy at 0.16ms latency — fast enough for real-time routing decisions |
| Session Manager | One-way trapdoor state machine ensuring PII-containing sessions are permanently locked to local inference, with cryptographic session ID hashing |
| Context Handoff | Rolling buffer mechanism preserving conversation continuity during mid-session cloud→local transitions, with optional PII scrubbing |
| Backend Manager | Pluggable selection strategies (priority, round-robin, latency-aware) with automatic health checking and failover |
| Shadow Mode | Non-blocking A/B comparison framework collecting quality metrics without impacting user-facing latency |
| Closed-Loop Controller | Rule-based recommendation engine that observes traffic patterns and suggests routing policy adjustments |
| Observability Stack | Full OpenTelemetry integration with Prometheus metrics, Grafana dashboards, and structured logging |
What the benchmarks revealed:
The evaluation across 200 synthetic prompts demonstrated that privacy-aware routing is feasible with sub-2ms overhead. The 68.6% cost savings from local routing validates the economic case, while the 10× latency penalty quantifies the privacy-performance trade-off. The systematic Tier 3 failures (health insurance IDs) highlight the importance of domain-specific pattern engineering and robust NER model selection — even with NER enabled, lightweight models may miss entities in specialized contexts.
This is not a production-ready system — it is a proof of architecture demonstrating that the building blocks exist and compose correctly.
8.2 Future Work
8.2.1 Scaling the Evaluation
The current benchmark uses 200 prompts — sufficient for detecting large effects but underpowered for tail behavior analysis. Future work should include:
| Benchmark | Purpose | Target |
|---|---|---|
| Extended classification | Rare pattern detection, edge cases | 1,000+ prompts |
| Load testing | Concurrent request handling, memory pressure | 100 req/s sustained |
| Adversarial evaluation | Evasion attempts, prompt injection | Red team dataset |
| Longitudinal study | Drift detection over weeks of traffic | Production deployment |
Statistical power analysis suggests n=1,000+ is required to detect failure modes occurring at <1% frequency with 95% confidence.
8.2.2 Improving NER Accuracy
The current implementation uses HuggingFace Transformers with dslim/bert-base-NER (“fast” mode, ~400MB) for named entity recognition. Several directions merit exploration:
| Model | Size | Tradeoff |
|---|---|---|
dslim/bert-base-NER (fast) |
~400MB | Current default, good speed, limited domain coverage |
Jean-Baptiste/roberta-large-ner-english (accurate) |
~1.3GB | Higher accuracy, 3-5× latency |
Davlan/bert-base-multilingual-cased-ner-hrl (multilingual) |
~700MB | Multi-language support |
| Fine-tuned NER | Variable | Domain-specific entities (PHI, financial identifiers) |
| Presidio | N/A | Microsoft’s PII detection library, rule + ML hybrid |
| GLiNER | 200MB | Zero-shot NER, no fine-tuning required |
The optimal choice depends on latency budget. For sub-50ms classification, the “fast” BERT model with expanded regex patterns may outperform larger models. For offline batch classification, RoBERTa-based NER (“accurate” mode) is viable.
8.2.3 GPU-Accelerated Local Inference
The current setup runs local models on Apple Silicon (M4 Mac Mini) using Metal acceleration via Ollama. While sufficient for development and low-throughput production, this architecture has limitations:
| Constraint | Current | With GPU |
|---|---|---|
| VRAM | 16GB unified | 24-80GB dedicated |
| Concurrent models | 1-2 (memory pressure) | 3-4+ |
| Throughput | ~0.1 req/s | 1-10 req/s |
| Model size | 4-8B parameters | 13-70B parameters |
GPU deployment options:
- NVIDIA GPU server (RTX 4090, A100): Run vLLM or TGI for high-throughput local inference
- Cloud GPU instances (but local network): AWS/GCP instances in private VPC, data never leaves controlled infrastructure
- Apple M4 Max/Ultra: 128GB unified memory enables 70B models with acceptable latency
The shadow mode quality metrics would likely improve significantly with larger local models, potentially enabling automatic traffic promotion.
8.2.4 Kubernetes Deployment
The current Docker Compose stack is suitable for single-node deployment. Production deployment requires:
┌─────────────────────────────────────────────────────────────┐
│ Kubernetes Cluster │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Sentinel │ │ Sentinel │ │ Sentinel │ │
│ │ Pod (HPA) │ │ Pod (HPA) │ │ Pod (HPA) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
│ └────────────────┼────────────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Redis (Session │ │
│ │ State) │ │
│ └─────────────────┘ │
│ │ │
│ ┌────────────────┼────────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Ollama │ │ Ollama │ │ vLLM │ │
│ │ (gemma3) │ │ (mistral) │ │ (llama3) │ │
│ │ Node 1 │ │ Node 2 │ │ GPU Node │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────┘
K8s-specific requirements:
- Horizontal Pod Autoscaler (HPA) for gateway pods based on request rate
- Node affinity for GPU-accelerated inference pods
- PodDisruptionBudget ensuring availability during rollouts
- NetworkPolicy restricting egress to approved cloud endpoints
- ServiceMesh (Istio/Linkerd) for mTLS between components
8.2.5 Session State: In-Memory vs. Persistent Storage
The current architecture stores session state in an in-memory data structure with TTL-based eviction. This is a deliberate design choice:
| Approach | Pros | Cons |
|---|---|---|
| In-memory (current) | Zero latency, no external dependencies, automatic cleanup | Lost on restart, single-node only |
| Redis | Distributed, persistent, TTL support native | Additional infra, latency (+1-2ms), security surface |
| PostgreSQL | ACID, queryable, audit trail | Highest latency, schema management, backup complexity |
Why in-memory is defensible:
- Session data is ephemeral by design — 15-minute TTL means losing state on restart is acceptable for most use cases
- Security through ephemerality — no persistent store means no data to exfiltrate, no backups to secure, no encryption-at-rest requirements
- Operational simplicity — no Redis cluster to manage, no connection pooling, no failover logic
- Latency — hash table lookup is O(1) with ~0.001ms; Redis adds network round-trip
When to move to Redis:
- Multi-pod deployment requiring shared session state
- Session TTL >1 hour (memory pressure)
- Audit requirements mandating session history
- Graceful restart without session loss
For the Redis migration path, the interface is already abstracted:
class SessionStore(Protocol):
async def get(self, session_id: str) -> Optional[Session]: ...
async def set(self, session_id: str, session: Session) -> None: ...
async def delete(self, session_id: str) -> None: ...
# Swap implementations without changing business logic
store = RedisSessionStore(redis_url) if USE_REDIS else InMemorySessionStore()
8.3 Target Applications
inference-sentinel addresses use cases across multiple organizational functions:
Healthcare & Life Sciences
| Use Case | Privacy Concern | Sentinel Solution |
|---|---|---|
| Clinical decision support | PHI in patient queries | Tier 3 classification for health records |
| Drug interaction lookup | Patient medication history | Session locking after first PHI exposure |
| Medical transcription | Dictated patient notes | Local inference for all transcription |
Regulatory context: HIPAA requires technical safeguards for PHI. A gateway that provably routes PHI to local-only inference provides auditable compliance.
Financial Services
| Use Case | Privacy Concern | Sentinel Solution |
|---|---|---|
| Customer service chatbots | Account numbers, SSNs | Tier 3 detection with immediate local routing |
| Fraud analysis | Transaction patterns | Shadow mode for quality validation before local promotion |
| Document summarization | Contracts with PII | Context handoff preserving conversation flow |
Regulatory context: PCI-DSS, SOX, and GLBA impose data handling requirements that a privacy-aware gateway can enforce at the infrastructure layer.
Legal & Professional Services
| Use Case | Privacy Concern | Sentinel Solution |
|---|---|---|
| Contract review | Client confidential information | Tier 2+ routing for all legal documents |
| Legal research | Case details, party names | Session stickiness ensuring full conversation stays local |
| E-discovery | Privileged communications | Mandatory local inference for attorney-client content |
Enterprise IT & Security
| Use Case | Privacy Concern | Sentinel Solution |
|---|---|---|
| Code review assistants | Proprietary source code | Internal URL and project code detection (Tier 1) |
| Security log analysis | Infrastructure details, credentials | API key and credential pattern detection (Tier 3) |
| Internal knowledge base Q&A | Employee PII, org structure | Configurable routing based on data classification |
Human Resources
| Use Case | Privacy Concern | Sentinel Solution |
|---|---|---|
| Resume screening | Candidate PII | Local inference for all recruitment workflows |
| Employee feedback analysis | Performance data | Session locking after employee identifier detection |
| Compensation benchmarking | Salary information | Tier 3 classification for financial PII |
8.4 Broader Impact
The proliferation of LLM-powered applications creates a tension between capability and privacy. Cloud-hosted models offer superior performance but require transmitting potentially sensitive data to third parties. Local models preserve privacy but sacrifice quality and increase operational burden.
inference-sentinel demonstrates that this is not a binary choice. By making routing decisions at inference time based on content classification, organizations can:
- Use cloud models for the 50%+ of traffic that contains no sensitive data — capturing the quality and cost benefits
- Enforce local-only inference for genuinely sensitive content — preserving privacy guarantees
- Measure the trade-off empirically — shadow mode quantifies exactly what quality you sacrifice for privacy
This is a fundamentally different approach from “all cloud” or “all local” architectures. It treats privacy as a first-class routing dimension, alongside latency and cost.
8.5 Closing Thoughts
Building inference-sentinel during my job search taught me more about LLM infrastructure than any tutorial could. Debugging why Ollama returns 404 (model name mismatch), why Grafana dashboards show “Value” instead of model names (missing metric labels), why round-robin wasn’t working (YAML override precedence) — these are the unglamorous details that separate working systems from prototypes.
The code is open source. The architecture is documented. The benchmarks are reproducible.
If you’re building LLM applications that handle sensitive data, I hope this work provides a useful reference — or at least saves you from repeating my mistakes.
Appendix A: Raw Data
A.1 Classification Misclassifications
All 5 errors follow the pattern:
- Input: Health record with insurance ID format
[A-Z]{3}\d{9} - Expected entities:
PERSON_NAME(not detected by BERT NER in medical context) - Detected entities:
[]
A.2 Routing Errors
All 17 errors: HTTP 503: No healthy local backends available
Distribution: 8 Tier 2, 9 Tier 3 (local-routed traffic only)
A.3 Entity Detection Summary
| Entity Type | Count | Tier Assignment |
|---|---|---|
| SSN | 24 | 3 |
| Credit Card | 12 | 3 |
| Health Record (MRN) | 6 | 3 |
| Bank Account | 6 | 3 |
| 18 | 2 | |
| Phone | 14 | 2 |
| Address | 16 | 2 |
| Internal URL | 28 | 1 |
| Project Code | 12 | 1 |
| Employee ID | 10 | 1 |
GitHub: github.com/kraghavan/inference-sentinel
Questions, feedback, or collaboration ideas? Connect on LinkedIn.
Updated Last: March 24, 2026