Building a Privacy-Aware LLM Gateway: Architecture Deep-Dive
Part 1 of 2: Design decisions, trade-offs, and lessons from building inference-sentinel
Why I Built This
During my job search, I wanted a project that would demonstrate distributed systems thinking — not just “I can call an API,” but “I can design a system that handles real production concerns.”
The problem I chose: How do you route LLM prompts intelligently based on data sensitivity, while maintaining session continuity and observability?
This post walks through every architectural decision I made building inference-sentinel, including the trade-offs I considered and the mistakes I made along the way.
System Overview
Design Diagram generated by NotebookLLM
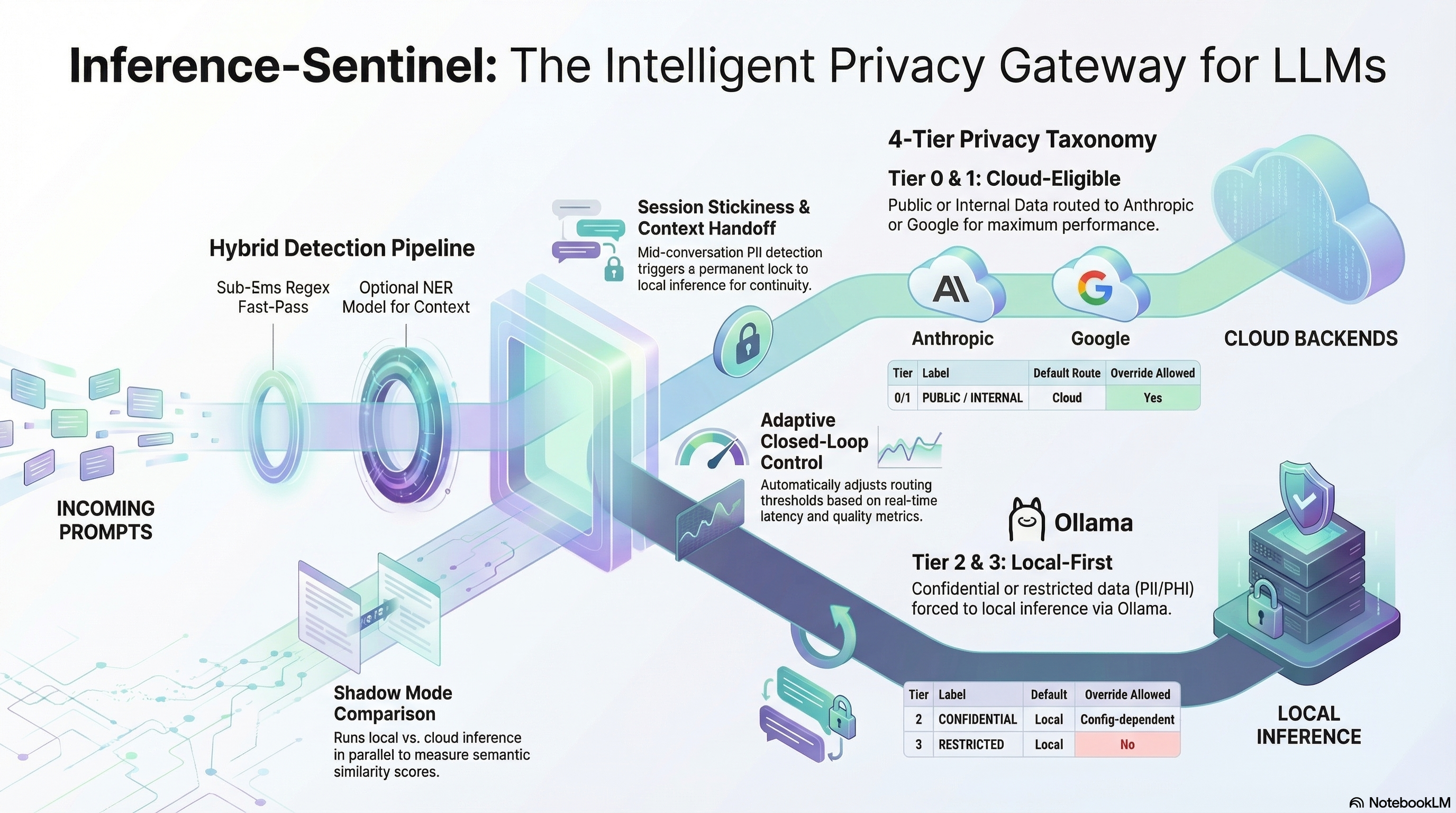 The Inference Sentinel architecture: privacy-aware routing with session stickiness and closed-loop control
The Inference Sentinel architecture: privacy-aware routing with session stickiness and closed-loop control
Components
┌─────────────────────────────────────────────────────────────────────────────┐
│ Application Layer │
│ (Any OpenAI-compatible client) │
└─────────────────────────────────────┬───────────────────────────────────────┘
│ POST /v1/inference
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ inference-sentinel │
│ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ Request Pipeline │ │
│ │ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ Hybrid │ │ Session │ │ Backend │ │ │
│ │ │ Classifier │───▶│ Manager │───▶│ Manager │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ • Regex │ │ • Trapdoor │ │ • Selection │ │ │
│ │ │ • NER │ │ • Buffer │ │ • Failover │ │ │
│ │ │ • Tier 0-3 │ │ • Handoff │ │ • Health │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ │ │ │ │ │ │
│ │ ▼ ▼ ▼ │ │
│ │ ┌─────────────────────────────────────────────────────────────────┐ │ │
│ │ │ Telemetry Collector │ │ │
│ │ │ Metrics │ Traces │ Logs (OpenTelemetry-native) │ │ │
│ │ └─────────────────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ Background Services │ │
│ │ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ Shadow │ │ Closed │ │ Health │ │ │
│ │ │ Mode │ │ Loop │ │ Check │ │ │
│ │ │ │ │ Controller │ │ Loop │ │ │
│ │ │ • A/B test │ │ │ │ │ │ │
│ │ │ • Compare │ │ • Evaluate │ │ • Poll │ │ │
│ │ │ • Metrics │ │ • Recommend │ │ • Failover │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
┌─────────────────┴─────────────────┐
▼ ▼
┌─────────────────────┐ ┌─────────────────────┐
│ Local Backends │ │ Cloud Backends │
│ │ │ │
│ ┌───────────────┐ │ │ ┌───────────────┐ │
│ │ Ollama │ │ │ │ Anthropic │ │
│ │ • gemma3:4b │ │ │ │ • Claude │ │
│ │ • mistral │ │ │ │ Sonnet 4 │ │
│ └───────────────┘ │ │ └───────────────┘ │
│ │ │ ┌───────────────┐ │
│ (Round-robin at │ │ │ Google │ │
│ equal priority) │ │ │ • Gemini │ │
│ │ │ │ 2.0 Flash │ │
└─────────────────────┘ │ └───────────────┘ │
│ │
│ (Round-robin or │
│ primary/fallback) │
└─────────────────────┘
Component 1: The Hybrid Classifier
The Problem
I needed to classify prompts into privacy tiers quickly and accurately. The obvious approaches each have limitations:
| Approach | Latency | Accuracy | Limitations |
|---|---|---|---|
| Regex only | <1ms | ~85% | Misses context, false negatives |
| LLM-based | 200-500ms | ~95% | Too slow for a gateway |
| NER only | 15-50ms | ~90% | Heavy for simple patterns |
My Solution: Two-Stage Pipeline
class HybridClassifier:
"""
Stage 1: Fast-path regex for obvious patterns
Stage 2: NER for context-dependent detection (optional)
"""
async def classify(self, text: str) -> HybridResult:
# Stage 1: Regex (always runs, ~0.2ms)
regex_result = self._regex.classify(text)
# Tier 3 detected by regex — skip NER, route local immediately
if self.skip_ner_on_tier3 and regex_result.tier >= 3:
return HybridResult(
tier=regex_result.tier,
detection_method="regex",
)
# Check if NER should run
if not self._should_run_ner(regex_result.tier):
return HybridResult(
tier=regex_result.tier,
detection_method="regex",
)
# Stage 2: NER for additional context (~15-30ms on CPU)
ner_result = await self._ner.classify(text)
# Merge entities from both, take highest tier
return self._merge_results(regex_result, ner_result)
Design Decision: Why Regex First?
Trade-off considered: I could run NER on everything for maximum accuracy, but:
- Latency budget: A gateway adds latency to every request. I targeted <5ms for classification on the fast path (regex-only).
- Resource cost: The NER classifier uses HuggingFace Transformers with BERT-based models (~400MB for the “fast” model, ~1.3GB for “accurate”). For high-throughput scenarios, this matters.
- Diminishing returns: Regex catches 70%+ of Tier 3 patterns (SSN, credit cards, API keys) with near-zero cost.
The insight: Regex handles the “obvious” cases; NER handles the “subtle” cases (person names, organizations). Running both in parallel would be faster but would waste resources when regex already found Tier 3 data.
The 4-Tier Taxonomy
| Tier | Name | Detection Method | Examples | Routing |
|---|---|---|---|---|
| 0 | PUBLIC | Default (no matches) | “Explain quantum computing” | Cloud |
| 1 | INTERNAL | Regex patterns | Internal URLs, project codes | Cloud |
| 2 | CONFIDENTIAL | NER + Regex | Person names (NER), emails, phones (regex) | Local (configurable) |
| 3 | RESTRICTED | Regex patterns | SSN, credit cards, health data | Local (enforced) |
Design Decision: Why 4 Tiers?
Trade-off considered: Simpler would be binary (sensitive/not-sensitive). More granular could be 10+ categories.
Why 4:
- Maps to common enterprise data classification schemes (Public/Internal/Confidential/Restricted)
- Allows nuanced routing rules (Tier 2 is configurable, Tier 3 is enforced)
- Shadow mode can target specific tiers for A/B testing
- Simple enough to reason about, granular enough to be useful
Regex Pattern Design
Patterns are loaded from config/privacy_taxonomy.yaml, allowing customization without code changes:
# Example Tier 3 patterns (loaded from YAML at startup)
TIER_3_PATTERNS = {
# Social Security Numbers (various formats)
"ssn": r'\b\d{3}-\d{2}-\d{4}\b',
"ssn_spoken": r'\b(?:social|ssn)[\s:]*\d{3}[\s-]?\d{2}[\s-]?\d{4}\b',
# Credit Cards (Luhn-valid patterns)
"credit_card": r'\b(?:4\d{3}|5[1-5]\d{2}|3[47]\d{2}|6(?:011|5\d{2}))'
r'[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}\b',
# API Keys (common prefixes)
"api_key": r'\b(?:sk-|pk_|api[_-]?key[_-]?)[a-zA-Z0-9]{20,}\b',
# Health identifiers
"medical_record": r'\b(?:MRN|patient[\s-]?id)[\s:]*[A-Z0-9]{6,}\b',
}
Lesson learned: The regex \b word boundary is essential. Without it, 123-45-6789 matches inside abc123-45-6789xyz, causing false positives.
Component 2: Session Manager (The One-Way Trapdoor)
The Problem
Per-request classification isn’t enough. Consider this conversation:
Turn 1: "Help me draft a cover letter" → Tier 0 → Cloud ✓
Turn 2: "Here's my resume" → Tier 1 → Cloud ✓
Turn 3: "My SSN is 123-45-6789" → Tier 3 → Local ✓
Turn 4: "Actually, format that differently" → Tier 0 → Cloud? ❌
Turn 4 references Turn 3’s SSN implicitly. If we route it to cloud, we’ve leaked context.
My Solution: One-Way State Machine
┌─────────────────────┐
│ │
┌──────────▶│ CLOUD_ELIGIBLE │
│ │ │
│ └──────────┬──────────┘
│ │
│ Tier 2/3 detected in any turn
│ │
│ ▼
│ ┌─────────────────────┐
NEVER │ │
│ │ LOCAL_LOCKED │
│ │ │
└───────────└─────────────────────┘
Key property: The transition is irreversible. Once a session is LOCAL_LOCKED, no subsequent classification — even Tier 0 — can unlock it.
Implementation
class SessionState(str, Enum):
"""Session routing state."""
CLOUD_ELIGIBLE = "cloud_eligible" # Can route to cloud
LOCAL_LOCKED = "local_locked" # Must route to local (PII detected)
@dataclass
class SessionInfo:
"""Session metadata and state."""
session_id: str # SHA-256 hash of client IP + daily salt
state: SessionState = SessionState.CLOUD_ELIGIBLE
created_at: datetime = field(default_factory=lambda: datetime.now(timezone.utc))
last_activity: datetime = field(default_factory=lambda: datetime.now(timezone.utc))
# Lock metadata
local_locked_at: Optional[datetime] = None
lock_trigger_tier: Optional[int] = None
lock_trigger_entities: list = field(default_factory=list)
# Backend stickiness (maintains round-robin consistency within session)
cloud_backend: Optional[str] = None # "anthropic" or "google"
local_backend: Optional[str] = None # "gemma" or "mistral"
def lock_to_local(self, tier: int, entities: list) -> None:
"""Lock session to local routing (one-way trapdoor)."""
if self.state == SessionState.LOCAL_LOCKED:
return # Already locked — no-op
self.state = SessionState.LOCAL_LOCKED
self.local_locked_at = datetime.now(timezone.utc)
self.lock_trigger_tier = tier
self.lock_trigger_entities = entities.copy()
class SessionManager:
"""Manages session state with TTL expiration."""
def __init__(
self,
ttl_seconds: int = 900, # 15 minutes default
lock_threshold_tier: int = 2, # Tier 2+ triggers lock
buffer_max_turns: int = 5,
buffer_max_chars: int = 4000,
):
# Sessions and buffers stored in separate TTL caches
self._sessions: TTLCache = TTLCache(maxsize=10000, ttl=ttl_seconds)
self._buffers: TTLCache = TTLCache(maxsize=10000, ttl=ttl_seconds)
self._lock_threshold_tier = lock_threshold_tier
async def update_session_state_async(
self,
client_ip: str,
tier: int,
entities: list,
) -> SessionInfo:
"""Update session state based on classification result.
Applies the one-way trapdoor: if tier >= threshold, locks to local.
"""
session = await self.get_or_create_session_async(client_ip)
# Check if this classification triggers a lock
if tier >= self._lock_threshold_tier and not session.is_local_locked:
session.lock_to_local(tier, entities)
return session
Design Decision: Why Hash Session IDs with Daily Salt?
Trade-off considered: Store client IPs as-is for debuggability vs. hash them for privacy.
Why hash with rotating salt:
- Client IPs are PII — storing them raw creates compliance risk
- Daily salt rotation prevents cross-day user tracking
- If the session store is compromised, hashed IDs reveal nothing
- Lookup is O(1) either way with a good hash
class DailySalt:
"""Manages daily-rotating salt for session ID generation."""
def hash_with_salt(self, value: str) -> str:
"""Hash a value with current salt."""
combined = f"{value}:{self._current_salt}"
return hashlib.sha256(combined.encode()).hexdigest()
def generate_session_id(client_ip: str) -> str:
"""Generate session ID from client IP with daily-rotating salt."""
salt = get_daily_salt()
return salt.hash_with_salt(client_ip)
Design Decision: TTL and Eviction
Trade-off considered: Long TTL preserves sessions across browser refreshes. Short TTL reduces memory footprint.
My choice: 15 minutes (900 seconds), configurable.
Reasoning:
- Most conversations complete within 15 minutes
- Matches typical “idle timeout” for sensitive applications
- Memory overhead: ~2KB per session × 10K sessions = 20MB (acceptable)
- Uses
TTLCachefromcachetoolsfor automatic expiration
Component 3: Context Handoff
The Problem
When a session locks mid-conversation, the local model has no context. It doesn’t know what the user was asking about.
But we can’t just forward the full conversation history — it contains the very PII we’re trying to protect.
My Solution: Rolling Buffer with Dual Bounding
@dataclass
class BufferEntry:
"""Single interaction in the buffer."""
role: str # "user" or "assistant"
content: str
timestamp: datetime = field(default_factory=lambda: datetime.now(timezone.utc))
tier: int = 0 # Classification tier when added
scrubbed: bool = False # Whether content was scrubbed before storage
char_count: int = field(init=False)
def __post_init__(self):
self.char_count = len(self.content)
class RollingBuffer:
"""Rolling buffer with dual bounding.
Bounded by:
1. Max turns (number of user+assistant pairs)
2. Max total characters (prevents massive payloads)
When either limit is exceeded, oldest entries are evicted.
"""
def __init__(
self,
max_turns: int = 5,
max_chars: int = 4000, # ~1000 tokens
scrub_before_store: bool = True,
):
self._max_turns = max_turns
self._max_chars = max_chars
self._entries: List[BufferEntry] = []
self._total_chars = 0
self._lock = threading.Lock()
def add(
self,
role: str,
content: str,
tier: int = 0,
scrubbed_content: Optional[str] = None,
) -> None:
"""Add an entry, evicting oldest if limits exceeded."""
final_content = scrubbed_content if scrubbed_content is not None else content
entry = BufferEntry(role=role, content=final_content, tier=tier)
with self._lock:
self._entries.append(entry)
self._total_chars += entry.char_count
# Enforce character limit (evict oldest until under limit)
while self._total_chars > self._max_chars and len(self._entries) > 1:
evicted = self._entries.pop(0)
self._total_chars -= evicted.char_count
# Enforce turn limit (evict oldest until under limit)
while self.turn_count > self._max_turns and len(self._entries) > 1:
evicted = self._entries.pop(0)
self._total_chars -= evicted.char_count
def format_for_handoff(self) -> str:
"""Format buffer with XML tags for injection into local model."""
if not self._entries:
return ""
with self._lock:
lines = []
for entry in self._entries:
role_tag = "user_message" if entry.role == "user" else "assistant_response"
lines.append(f"<{role_tag}>{entry.content}</{role_tag}>")
return "\n".join(lines)
Design Decision: Dual Bounding vs. Simple Truncation
Trade-off considered:
| Option | Pros | Cons |
|---|---|---|
Simple truncation ([:max_chars]) |
Easy to implement | Cuts mid-sentence, loses coherence |
| Turn-based only | Clean turn boundaries | Unbounded if turns are long |
| Dual bounding (turns + chars) | Predictable memory, clean boundaries | More complex eviction logic |
My choice: Dual bounding — limit both turns (5) and total characters (4000).
Reasoning:
- Evicting oldest complete entries preserves coherence (no mid-sentence cuts)
- Character limit prevents a single massive turn from blowing up context
- Both limits are configurable per deployment
- ~4000 chars ≈ 1000 tokens, safe for even small local models
Design Decision: XML Tags for Context Injection
Why XML tags instead of plain text?
Plain text (ambiguous):
User: Help me with X
Assistant: Sure, here's how...
User: Now do Y
XML-tagged (unambiguous):
<user_message>Help me with X</user_message>
<assistant_response>Sure, here's how...</assistant_response>
<user_message>Now do Y</user_message>
Reasoning: Local models (especially smaller ones) can confuse injected history with their own output. XML tags create clear structural boundaries that even 4B parameter models respect.
PII Scrubbing with Deterministic Placeholders
def scrub_content_for_buffer(
content: str,
detected_entities: List[dict],
) -> str:
"""Scrub sensitive entities with hash-based placeholders.
Creates deterministic placeholders so the same entity gets
the same placeholder across turns (maintains referential coherence).
"""
if not detected_entities:
return content
scrubbed = content
# Sort by length descending to handle overlapping matches
sorted_entities = sorted(
detected_entities,
key=lambda e: len(e.get("value", "")),
reverse=True,
)
for entity in sorted_entities:
value = entity.get("value", "")
entity_type = entity.get("type", "REDACTED")
if value and value in scrubbed:
# Deterministic placeholder from hash
hash_suffix = hashlib.sha256(value.encode()).hexdigest()[:6]
placeholder = f"[{entity_type.upper()}_{hash_suffix}]"
scrubbed = scrubbed.replace(value, placeholder)
return scrubbed
Why hash-based placeholders?
| Approach | Example | Problem |
|---|---|---|
| Simple redaction | [REDACTED] |
“Send to [REDACTED] and CC [REDACTED]” — which is which? |
| Numbered | [PERSON_1], [PERSON_2] |
Requires state tracking across turns |
| Hash-based | [PERSON_a3f2c1] |
Same entity → same placeholder, stateless |
The hash suffix preserves referential identity: if “John Smith” appears in turns 1 and 3, both become [PERSON_a3f2c1], so the local model understands they refer to the same entity.
Full Handoff System Prompt
The actual handoff injects a complete system prompt with capability guardrails:
def create_handoff_system_prompt(
buffer: RollingBuffer,
capability_guardrail: bool = True,
) -> str:
"""Create system prompt for local model handoff."""
parts = []
# Capability guardrail (what the local model cannot do)
if capability_guardrail:
parts.append("""<capability_restrictions>
You are operating in a SECURE LOCAL environment with the following restrictions:
- You have NO access to the internet or web browsing
- You have NO access to external APIs or services
- You have NO access to databases or file systems
- You CANNOT make HTTP requests or fetch external data
- You MUST answer based solely on your training knowledge and the conversation context
If the user asks for anything requiring external access, politely explain
that you cannot perform that action in this secure environment.
</capability_restrictions>
""")
# Historical context from buffer
history = buffer.format_for_handoff()
if history:
parts.append(f"""<historical_context>
The following is the conversation history from this session.
{history}
</historical_context>
""")
# Current request instructions
parts.append("""<instructions>
Respond to the user's current message below. Maintain conversational
context from the history if provided. Be helpful, accurate, and concise.
</instructions>
""")
return "\n".join(parts)
Design Decision: Capability Guardrails
Why inject capability restrictions?
When a session locks to local, the user might still ask “search the web for X” or “check my calendar.” Without guardrails, the local model might:
- Hallucinate search results
- Pretend it has capabilities it doesn’t
- Confuse the user about what happened
The capability guardrail ensures the local model responds honestly: “I can’t access the web in this secure environment.”
Component 4: Backend Manager
The Problem
I needed to support multiple backends with different selection strategies:
- Local: Multiple Ollama models (gemma3:4b, mistral) on the same machine
- Cloud: Anthropic (claude-sonnet-4) and Google (gemini-2.0-flash) with configurable selection
Architecture: Separate Local and Cloud Management
class BackendManager:
"""Manages multiple inference backends with health checking and selection."""
def __init__(
self,
config: LocalBackendsConfig,
cloud_selection_strategy: Literal["primary_fallback", "round_robin"] = "primary_fallback",
cloud_primary: str = "anthropic",
cloud_fallback: str = "google",
):
self._config = config
self._local_backends: dict[str, OllamaBackend] = {}
self._cloud_backends: dict[str, BaseBackend] = {}
self._health_status: dict[str, bool] = {}
# Cloud selection config
self._cloud_selection_strategy = cloud_selection_strategy
self._cloud_primary = cloud_primary
self._cloud_fallback = cloud_fallback
# Round-robin state (separate counters for local and cloud)
self._cloud_rr_index: int = 0
self._local_rr_index: int = 0
self._lock = asyncio.Lock()
Selection Strategies
Local backends support three strategies (from config):
async def select_local_backend(
self,
strategy: Literal["priority", "round_robin", "latency_best"] | None = None,
) -> OllamaBackend | None:
"""Select a local backend based on the configured strategy."""
strategy = strategy or self._config.selection_strategy
healthy = self.get_healthy_local_backends()
if not healthy:
return None
if strategy == "priority":
# Sort by priority value from config, lowest wins
sorted_backends = sorted(
healthy,
key=lambda b: next(
e.priority for e in self._config.endpoints if e.name == b.endpoint_name
),
)
return sorted_backends[0]
elif strategy == "round_robin":
async with self._lock:
backend = healthy[self._local_rr_index % len(healthy)]
self._local_rr_index += 1
return backend
elif strategy == "latency_best":
# TODO: Implement actual latency tracking
return healthy[0]
return healthy[0]
Cloud backends support two strategies:
def select_cloud_backend(self, preferred: str | None = None) -> BaseBackend | None:
"""Select a cloud backend based on configured strategy.
Strategies:
- primary_fallback: Try primary (anthropic), then fallback (google)
- round_robin: Alternate between healthy backends
"""
healthy = self.get_healthy_cloud_backends()
if not healthy:
return None
# If preferred backend specified and healthy, use it
if preferred and preferred in self._cloud_backends:
backend = self._cloud_backends[preferred]
if self._health_status.get(preferred, False):
return backend
# Apply selection strategy
if self._cloud_selection_strategy == "round_robin":
return self._select_cloud_round_robin(healthy)
else:
# primary_fallback (default)
return self._select_cloud_primary_fallback(healthy)
Design Decision: Why Separate Local and Cloud Selection?
Trade-off considered:
| Approach | Pros | Cons |
|---|---|---|
| Unified strategy | Simpler code, one enum | Cloud and local have different needs |
| Separate strategies | Tailored to each tier | More configuration surface |
My choice: Separate strategies.
Reasoning:
- Local models are interchangeable: gemma3:4b and mistral are both “good enough” — round-robin makes sense
- Cloud models differ significantly: Anthropic Claude excels at reasoning; Gemini excels at speed and multimodal — primary/fallback lets me choose
- Cost considerations: Cloud round-robin might accidentally route expensive requests to the pricier provider
- Session stickiness: Cloud backends benefit from sticky routing (consistent model personality within a session)
Session-Sticky Backend Selection
The backend manager supports session stickiness — once a session uses a specific backend, subsequent requests prefer that backend:
async def generate_cloud(
self,
messages: list[dict],
preferred_backend: str | None = None,
sticky_backend: str | None = None, # From session state
) -> tuple[InferenceResult, BaseBackend | None]:
"""Generate using cloud with optional stickiness."""
# Sticky backend takes precedence over preferred
effective_preferred = sticky_backend or preferred_backend
backend = self.select_cloud_backend(effective_preferred)
# ... rest of generation
Why stickiness matters:
- Model personality consistency within a conversation
- Avoids jarring style shifts mid-conversation
- Round-robin still applies to new sessions
Health Checking
async def refresh_health(self) -> dict[str, bool]:
"""Refresh health status for all backends concurrently."""
# Build tasks for all backends
local_tasks = {
name: backend.health_check()
for name, backend in self._local_backends.items()
}
cloud_tasks = {
name: backend.health_check()
for name, backend in self._cloud_backends.items()
}
all_tasks = {**local_tasks, **cloud_tasks}
# Run all health checks concurrently
results = await asyncio.gather(*all_tasks.values(), return_exceptions=True)
for name, result in zip(all_tasks.keys(), results):
if isinstance(result, Exception):
self._health_status[name] = False
else:
self._health_status[name] = result
return self._health_status.copy()
For Ollama, the health check hits /api/tags and verifies the configured model is available:
async def health_check(self) -> bool:
"""Check if Ollama is healthy and the model is available."""
try:
client = await self._get_client()
response = await client.get("/api/tags")
response.raise_for_status()
data = response.json()
models = [m["name"] for m in data.get("models", [])]
# Check if our configured model is available
model_available = any(
self._endpoint.model in m or m in self._endpoint.model
for m in models
)
return model_available
except Exception:
return False
Design Decision: Ping vs. Inference Health Check
Trade-off considered:
| Method | Pros | Cons |
|---|---|---|
HTTP ping (/api/tags) |
Fast (~10ms), low overhead | Doesn’t verify model is loaded in memory |
| Minimal inference | Verifies end-to-end | Slow (~2s), wastes compute |
My choice: HTTP ping to Ollama’s /api/tags endpoint, then verify model is in the list.
Reasoning: Ollama keeps models in memory after first load. If the HTTP endpoint responds and lists our model, it’s ready. Full inference check would add ~2s per model per check cycle.
Cross-Tier Failover
The backend manager supports failing over from cloud to local if all cloud backends fail:
async def generate_routed(
self,
messages: list[dict],
route: Literal["local", "cloud"],
preferred_cloud_backend: str | None = None,
sticky_backend: str | None = None,
) -> tuple[InferenceResult, BaseBackend | None, Literal["local", "cloud"]]:
"""Generate with automatic failover."""
if route == "cloud":
result, backend = await self.generate_cloud(
messages, preferred_cloud_backend, sticky_backend
)
if result.error and self._config.failover_enabled:
# Fallback to local if cloud fails
logger.info("Cloud failed, falling back to local")
result, backend = await self.generate(messages, sticky_backend=sticky_backend)
return result, backend, "local" # Note: actual route changed
return result, backend, "cloud"
else:
result, backend = await self.generate(messages, sticky_backend=sticky_backend)
return result, backend, "local"
Why cloud → local failover?
- Graceful degradation: If Anthropic and Google both have outages, users still get responses
- Tier 0-1 traffic is safe for local: No PII, so local fallback doesn’t violate privacy
- Return actual route: Caller knows the response came from local, not cloud (important for billing, metrics)
Component 5: Shadow Mode
The Problem
How do I know if local inference is “good enough” to replace cloud for certain traffic?
My Solution: Sequential Execution with Background Comparison
User Request (Tier 0 or 1)
│
▼
Cloud Backend ────────────▶ Response to User (immediate)
│
│ (cloud result captured)
│
▼
┌──────────────────┐
│ Fire-and-Forget │
│ Background Task │
└────────┬─────────┘
│
▼
Local Backend ──────────▶ Compare ──────────▶ Log Metrics
(async, non-blocking)
Key insight: Shadow mode is NOT truly parallel. Cloud executes first, returns to user immediately, THEN the shadow task is triggered with the cloud result passed in. This ensures zero latency impact on the user.
Implementation
@dataclass
class ShadowConfig:
"""Configuration for shadow mode."""
enabled: bool = False
# Which tiers to shadow (only safe tiers)
shadow_tiers: list[int] = field(default_factory=lambda: [0, 1])
# Sampling rate (0.0 to 1.0)
sample_rate: float = 1.0 # 100% of eligible requests
# Similarity scoring
similarity_enabled: bool = True
similarity_model: str = "fast" # "fast", "balanced", "accurate"
# Timeouts
local_timeout_seconds: float = 60.0
# Storage
store_responses: bool = False # Memory heavy
max_stored_results: int = 1000
class ShadowRunner:
"""Runs shadow mode comparisons between local and cloud models.
Shadow mode is non-blocking - cloud response is returned immediately
while local inference runs in the background.
"""
def __init__(self, config: ShadowConfig | None = None):
self.config = config or ShadowConfig()
self._similarity = get_similarity_scorer()
# Results storage (circular buffer)
self._results: list[ShadowResult] = []
# Background tasks tracking
self._pending_tasks: set[asyncio.Task] = set()
# Internal metrics
self._total_shadows = 0
self._successful_shadows = 0
self._quality_matches = 0
self._total_cost_savings = 0.0
def should_shadow(self, privacy_tier: int) -> bool:
"""Determine if this request should be shadowed."""
if not self.config.enabled:
return False
# Only shadow safe tiers (0 and 1 by default)
if privacy_tier not in self.config.shadow_tiers:
return False
# Apply sampling rate
if self.config.sample_rate < 1.0:
import random
if random.random() > self.config.sample_rate:
return False
return True
async def run_shadow(
self,
request_id: str,
messages: list[dict],
cloud_result: InferenceResult, # Cloud result already available
cloud_backend_name: str,
cloud_latency_ms: float,
privacy_tier: int,
backend_manager: BackendManager,
) -> None:
"""Run shadow inference on local backend.
This method is fire-and-forget — it schedules the shadow
task and returns immediately.
"""
task = asyncio.create_task(
self._run_shadow_async(
request_id=request_id,
messages=messages,
cloud_result=cloud_result,
cloud_backend_name=cloud_backend_name,
cloud_latency_ms=cloud_latency_ms,
privacy_tier=privacy_tier,
backend_manager=backend_manager,
)
)
# Track task for cleanup
self._pending_tasks.add(task)
task.add_done_callback(self._pending_tasks.discard)
Design Decision: Why Sequential, Not Parallel?
Trade-off considered:
| Approach | User latency impact | Resource usage | Implementation |
|---|---|---|---|
| True parallel (both start together) | +0ms (but ties up local) | 2x concurrent | Complex coordination |
| Sequential (cloud first, then shadow) | +0ms | 1x then 1x | Simple, clean |
My choice: Sequential with fire-and-forget.
Reasoning:
- User doesn’t wait: Cloud returns immediately; shadow runs after
- Simpler state: Shadow receives cloud result directly, no coordination needed
- Resource efficient: Local inference only starts after cloud completes
- Timeout is per-shadow: If local times out, we just lose that data point
Shadow Result Structure
@dataclass
class ShadowResult:
"""Result of a shadow mode comparison."""
# Identifiers
shadow_id: str
request_id: str
timestamp: str
# Models used
cloud_model: str
local_model: str
cloud_backend: str
local_backend: str
# Latency comparison
cloud_latency_ms: float
local_latency_ms: float
latency_diff_ms: float # local - cloud (negative = local faster)
# Cost comparison
cloud_cost_usd: float
local_cost_usd: float # Usually 0 for local
cost_savings_usd: float
# Quality comparison
similarity: SimilarityResult | None = None
@property
def is_quality_match(self) -> bool:
"""Check if local quality matches cloud (threshold: 0.75)."""
if self.similarity is None:
return False
return self.similarity.is_quality_match
@property
def local_is_faster(self) -> bool:
"""Check if local was faster than cloud."""
return self.latency_diff_ms < 0
Similarity Computation with Sentence Transformers
class SimilarityScorer:
"""Computes semantic similarity using sentence-transformers."""
# Available models (speed vs accuracy tradeoff)
MODELS = {
"fast": "all-MiniLM-L6-v2", # 80MB, 384 dims
"balanced": "all-mpnet-base-v2", # 420MB, 768 dims
"accurate": "all-roberta-large-v1", # 1.3GB, 1024 dims
}
# Similarity interpretation thresholds
THRESHOLDS = {
"high": 0.85, # Responses are very similar
"medium": 0.70, # Responses convey similar meaning
"low": 0.0, # Responses differ significantly
}
async def compute_similarity(
self,
cloud_response: str,
local_response: str,
) -> SimilarityResult:
"""Compute semantic similarity between two responses."""
# Load model lazily
if not self._initialized:
await self.initialize()
# Compute embeddings in thread pool (CPU-bound)
loop = asyncio.get_event_loop()
embeddings = await loop.run_in_executor(
None,
lambda: self._model.encode(
[cloud_response, local_response],
convert_to_numpy=True,
normalize_embeddings=True, # Pre-normalize for dot product
)
)
# Cosine similarity (embeddings are normalized, so dot product suffices)
similarity = float(np.dot(embeddings[0], embeddings[1]))
# Clamp to [0, 1] and interpret
similarity = max(0.0, min(1.0, similarity))
if similarity >= self.THRESHOLDS["high"]:
interpretation = "high"
elif similarity >= self.THRESHOLDS["medium"]:
interpretation = "medium"
else:
interpretation = "low"
return SimilarityResult(
similarity_score=similarity,
interpretation=interpretation,
# ... other fields
)
Design Decision: Why Sentence Transformers?
Trade-off considered:
| Approach | Speed | Quality | Dependencies |
|---|---|---|---|
| Jaccard similarity | <1ms | Poor (surface only) | None |
| TF-IDF + cosine | ~5ms | Moderate | sklearn |
| Sentence transformers | ~50ms | Excellent (semantic) | torch, transformers |
My choice: Sentence transformers with model tiers.
Reasoning:
- Semantic similarity matters: “The cat sat on the mat” and “A feline rested on the rug” should score high
- Model flexibility: “fast” (80MB) for development, “accurate” (1.3GB) for production validation
- Lazy loading: Model only loads when first shadow comparison runs
- Thread pool execution: Embeddings computed off the event loop to avoid blocking
Quality Match Threshold
@property
def is_quality_match(self) -> bool:
"""Check if responses are semantically similar enough."""
return self.similarity_score >= 0.75
Why 0.75?
| Threshold | Meaning | Risk |
|---|---|---|
| 0.90+ | Near-identical | Too strict, almost never matches |
| 0.80-0.90 | Very similar | Good for production validation |
| 0.70-0.80 | Similar meaning | Acceptable for most use cases |
| <0.70 | Different responses | Quality concern |
I chose 0.75 as a balance — strict enough to catch quality regressions, loose enough to tolerate stylistic differences between models.
Internal Metrics for Controller
The ShadowRunner maintains internal metrics that the controller reads directly (no Prometheus dependency):
def get_metrics(self) -> dict:
"""Get shadow mode metrics for controller."""
quality_rate = (
self._quality_matches / self._successful_shadows
if self._successful_shadows > 0 else 0.0
)
return {
"total_shadows": self._total_shadows,
"successful_shadows": self._successful_shadows,
"quality_matches": self._quality_matches,
"quality_match_rate": round(quality_rate, 4),
"total_cost_savings_usd": round(self._total_cost_savings, 4),
"pending_tasks": len(self._pending_tasks),
"stored_results": len(self._results),
}
Component 6: Closed-Loop Controller
The Problem
Shadow mode generates data. But who acts on it?
Manual review doesn’t scale. I wanted a system that could observe patterns and generate routing recommendations automatically.
Architecture
┌─────────────────────────────────────────────────────────────────┐
│ Closed-Loop Controller │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Metrics │ │ Rule │ │ Recommend- │ │
│ │ Reader │───▶│ Engine │───▶│ ations │ │
│ │ │ │ │ │ │ │
│ │ • Read from │ │ • Evaluate │ │ • Generate │ │
│ │ Shadow │ │ per-tier │ │ • Log │ │
│ │ Runner │ │ • Threshold │ │ • (Act)* │ │
│ │ directly │ │ • Drift │ │ │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │
│ *Act is disabled in "observe" mode (v1) │
│ No Prometheus dependency — pure Python state access │
└──────────────────────────────────────────────────────────────────┘
Key design point: The controller reads metrics directly from ShadowRunner._results, NOT from Prometheus. This eliminates an external dependency and simplifies deployment.
Metrics Reader: Direct State Access
class MetricsReader:
"""Reads and aggregates metrics from ShadowRunner internal state.
No Prometheus dependency — pure Python state access.
Uses timestamped filtering for rolling window calculations.
"""
def __init__(self, window_seconds: int = 300):
"""Initialize metrics reader.
Args:
window_seconds: Rolling window size in seconds (default: 5 min)
"""
self._window_seconds = window_seconds
self._shadow_runner: ShadowRunner | None = None
self._previous_tier_metrics: dict[int, TierMetrics] = {}
def set_shadow_runner(self, runner: ShadowRunner) -> None:
"""Set the shadow runner to read metrics from."""
self._shadow_runner = runner
def get_tier_metrics(
self,
tier: int,
window_seconds: int | None = None,
quality_threshold: float = 0.85,
) -> TierMetrics:
"""Get aggregated metrics for a specific tier."""
window = window_seconds or self._window_seconds
cutoff = datetime.now(timezone.utc) - timedelta(seconds=window)
# Read directly from shadow runner's internal results
samples = self._collect_samples(tier, cutoff)
if not samples:
return TierMetrics(tier=tier)
# Calculate statistics
similarities = [s.similarity_score for s in samples]
return TierMetrics(
tier=tier,
sample_count=len(samples),
avg_similarity=mean(similarities),
min_similarity=min(similarities),
max_similarity=max(similarities),
p50_similarity=median(similarities),
quality_match_rate=len([s for s in samples if s.similarity_score >= quality_threshold]) / len(samples),
# ... other fields
)
def _collect_samples(self, tier: int, cutoff: datetime) -> list[MetricsSample]:
"""Collect samples by reading ShadowRunner._results directly."""
if not self._shadow_runner:
return []
samples = []
results = getattr(self._shadow_runner, "_results", [])
for result in results:
result_time = self._parse_timestamp(result.timestamp)
if result_time and result_time >= cutoff and result.privacy_tier == tier:
samples.append(MetricsSample(
tier=result.privacy_tier,
similarity_score=result.similarity.similarity_score if result.similarity else 0.0,
latency_diff_ms=result.latency_diff_ms,
cost_savings_usd=result.cost_savings_usd,
is_quality_match=result.is_quality_match,
timestamp=result_time,
))
return samples
Design Decision: Why Not Prometheus?
Trade-off considered:
| Approach | Pros | Cons |
|---|---|---|
| Query Prometheus | Industry standard, dashboards built-in | External dependency, network latency |
| Read ShadowRunner directly | Zero dependencies, faster, simpler | Tighter coupling, no persistence |
My choice: Direct state access.
Reasoning:
- Simplicity: Controller runs in same process as ShadowRunner — no network hop
- Deployment: One less service to configure and maintain
- Latency: Sub-millisecond access vs. Prometheus query latency
- Portfolio scope: Demonstrating the pattern is sufficient; production might add Prometheus for persistence
Rule Engine
class RecommendationType(Enum):
"""Types of routing recommendations."""
ROUTE_TO_LOCAL = "route_to_local" # Quality good, save money
KEEP_ON_CLOUD = "keep_on_cloud" # Quality insufficient
DRIFT_ALERT = "drift_alert" # Quality degraded from previous
INSUFFICIENT_DATA = "insufficient_data" # Need more samples
NO_CHANGE = "no_change" # Current config is optimal
class Confidence(Enum):
"""Confidence level for recommendations."""
HIGH = "high" # >500 samples, stable metrics
MEDIUM = "medium" # 100-500 samples
LOW = "low" # <100 samples
class RuleEngine:
"""Evaluates metrics against rules to generate recommendations."""
def __init__(self, config: ControllerConfig):
self._config = config
def evaluate(
self,
current: TierMetrics,
previous: TierMetrics | None = None,
) -> Recommendation:
"""Evaluate metrics for a tier and generate recommendation."""
ctx = RuleContext(
current_metrics=current,
previous_metrics=previous,
config=self._config,
tier=current.tier,
)
# Rule priority: check in order
# 1. Insufficient data
if self._check_insufficient_data(ctx):
min_samples = ctx.threshold_config.get("min_samples", 100)
return Recommendation(
tier=ctx.tier,
recommendation=RecommendationType.INSUFFICIENT_DATA,
reason=f"Only {current.sample_count} samples, need {min_samples}",
confidence=Confidence.LOW,
)
# 2. Drift alert (quality degradation)
if self._check_drift(ctx):
delta = previous.avg_similarity - current.avg_similarity
return Recommendation(
tier=ctx.tier,
recommendation=RecommendationType.DRIFT_ALERT,
reason=f"Quality degraded by {delta:.1%}",
confidence=self._get_confidence(current.sample_count),
previous_similarity=previous.avg_similarity,
similarity_delta=-delta,
)
# 3. Route to local (quality good + cost savings)
if self._check_route_to_local(ctx):
return Recommendation(
tier=ctx.tier,
recommendation=RecommendationType.ROUTE_TO_LOCAL,
reason=f"Similarity {current.avg_similarity:.1%} exceeds threshold",
confidence=self._get_confidence(current.sample_count),
potential_savings_usd=current.total_cost_savings_usd,
)
# 4. Keep on cloud (quality insufficient)
if self._check_keep_on_cloud(ctx):
min_similarity = ctx.threshold_config.get("min_similarity", 0.85)
gap = min_similarity - current.avg_similarity
return Recommendation(
tier=ctx.tier,
recommendation=RecommendationType.KEEP_ON_CLOUD,
reason=f"Similarity {current.avg_similarity:.1%} is {gap:.1%} below threshold",
confidence=self._get_confidence(current.sample_count),
)
# 5. No change needed
return Recommendation(
tier=ctx.tier,
recommendation=RecommendationType.NO_CHANGE,
reason="Current configuration is optimal",
confidence=self._get_confidence(current.sample_count),
)
def _get_confidence(self, sample_count: int) -> Confidence:
"""Determine confidence level based on sample count."""
if sample_count >= 500:
return Confidence.HIGH
elif sample_count >= 100:
return Confidence.MEDIUM
return Confidence.LOW
Controller Configuration
@dataclass
class ControllerConfig:
"""Configuration for the closed-loop controller."""
enabled: bool = False
mode: Literal["observe", "auto"] = "observe"
evaluation_interval_seconds: int = 60
window_seconds: int = 300 # 5 minute rolling window
# Per-tier thresholds (different tiers can have different quality bars)
tier_thresholds: dict[int, dict] = field(default_factory=lambda: {
0: {"min_similarity": 0.85, "min_samples": 100},
1: {"min_similarity": 0.80, "min_samples": 100},
})
# Alert thresholds
drift_threshold: float = 0.10 # Alert if similarity drops by 10%
cost_savings_threshold_usd: float = 50.0 # Min savings to recommend
Controller Lifecycle
class ClosedLoopController:
"""Closed-loop controller for routing optimization.
Runs as asyncio background task within FastAPI lifecycle.
"""
async def start(self) -> None:
"""Start the controller background task."""
if not self._config.enabled:
logger.info("Controller disabled, not starting")
return
self._running = True
self._task = asyncio.create_task(self._run_loop())
async def _run_loop(self) -> None:
"""Main controller loop — runs evaluation at configured interval."""
while self._running:
try:
await self._evaluate()
except Exception as e:
logger.error("Controller evaluation failed", error=str(e))
await asyncio.sleep(self._config.evaluation_interval_seconds)
async def _evaluate(self) -> None:
"""Run a single evaluation cycle."""
self._total_evaluations += 1
self._last_evaluation = datetime.utcnow()
# Collect metrics for all tiers
tier_metrics = self._metrics_reader.get_all_tier_metrics()
if not tier_metrics:
logger.debug("No shadow metrics available for evaluation")
return
# Evaluate each tier
for tier, metrics in tier_metrics.items():
previous = self._metrics_reader.get_previous_metrics(tier)
recommendation = self._rule_engine.evaluate(metrics, previous)
# Log recommendation (structured for Loki)
self._log_recommendation(recommendation, metrics)
# Store current metrics for next evaluation's drift detection
self._metrics_reader.store_current_as_previous(tier_metrics)
async def force_evaluate(self) -> dict:
"""Force an immediate evaluation (for testing/debugging)."""
await self._evaluate()
return {
"evaluation_number": self._total_evaluations,
"recommendations": {
tier: rec.to_dict()
for tier, rec in self._current_recommendations.items()
},
}
Design Decision: Observe vs Auto Mode
Trade-off considered:
| Mode | Behavior | Risk |
|---|---|---|
| Observe | Log recommendations only | None (human reviews) |
| Auto | Adjust routing weights automatically | Runaway feedback loops |
My choice: Observe mode only for v1.
Reasoning: Auto-routing is powerful but dangerous. A bug in similarity computation could cause the controller to route all traffic to local, degrading user experience. For a portfolio project, demonstrating the architecture is sufficient. Production deployment would require:
- Extensive testing of the feedback loop
- Circuit breakers to prevent runaway changes
- Gradual rollout (route 1% to local, measure, increase)
- Human approval gates for significant changes
Component 7: Observability Stack
Architecture: Three Pillars
The gateway implements all three observability pillars:
| Pillar | Library | Export Target | Purpose |
|---|---|---|---|
| Metrics | prometheus_client |
Prometheus | Counters, histograms, gauges |
| Traces | OpenTelemetry | Tempo (OTLP) | Request flow, latency breakdown |
| Logs | structlog |
Loki (JSON) | Events, debugging |
Note: Metrics use prometheus_client (Prometheus-native), NOT OpenTelemetry. This is intentional — Prometheus client is more mature and Grafana dashboards work seamlessly with it.
Metrics: Prometheus-Native
from prometheus_client import Counter, Histogram, Gauge, Info
# =============================================================================
# Request Metrics
# =============================================================================
REQUESTS_TOTAL = Counter(
"sentinel_requests_total",
"Total number of inference requests",
labelnames=["route", "backend", "endpoint", "model", "tier", "status"]
)
REQUESTS_IN_PROGRESS = Gauge(
"sentinel_requests_in_progress",
"Number of requests currently being processed",
labelnames=["backend"]
)
# =============================================================================
# Latency Metrics (LLM-specific histograms)
# =============================================================================
LATENCY_BUCKETS_SEC = [0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0, 2.5, 5.0, 10.0, 30.0, 60.0]
TTFT_SECONDS = Histogram(
"sentinel_ttft_seconds",
"Time to first token in seconds",
labelnames=["backend", "endpoint", "model"],
buckets=LATENCY_BUCKETS_SEC
)
ITL_SECONDS = Histogram(
"sentinel_itl_seconds",
"Inter-token latency in seconds",
labelnames=["backend", "endpoint", "model"],
buckets=[0.005, 0.010, 0.020, 0.030, 0.050, 0.075, 0.100, 0.150, 0.200, 0.500]
)
TPOT_SECONDS = Histogram(
"sentinel_tpot_seconds",
"Time per output token in seconds",
labelnames=["backend", "endpoint", "model"],
buckets=[0.005, 0.010, 0.020, 0.030, 0.050, 0.075, 0.100, 0.150, 0.200, 0.500]
)
CLASSIFICATION_LATENCY_SECONDS = Histogram(
"sentinel_classification_latency_seconds",
"Privacy classification latency in seconds",
labelnames=["detection_method"],
buckets=[0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1]
)
# =============================================================================
# Shadow Mode Metrics
# =============================================================================
SHADOW_REQUESTS_TOTAL = Counter(
"sentinel_shadow_requests_total",
"Total shadow mode comparisons",
labelnames=["status"] # success, timeout, error
)
SHADOW_SIMILARITY_SCORE = Histogram(
"sentinel_shadow_similarity_score",
"Semantic similarity score between cloud and local outputs",
buckets=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0]
)
SHADOW_QUALITY_MATCH = Counter(
"sentinel_shadow_quality_match_total",
"Shadow comparisons where local quality matched cloud",
labelnames=["tier"]
)
# =============================================================================
# Cost Metrics
# =============================================================================
COST_USD_TOTAL = Counter(
"sentinel_cost_usd_total",
"Total inference cost in USD",
labelnames=["backend", "model"]
)
COST_SAVINGS_USD_TOTAL = Counter(
"sentinel_cost_savings_usd_total",
"Total cost savings from local routing in USD"
)
Helper Functions for Clean Recording
Rather than scattering metric updates throughout the codebase, I centralized them:
def record_request(
route: str,
backend: str,
endpoint: str,
model: str,
tier: int,
status: str = "success"
) -> None:
"""Record a completed request."""
REQUESTS_TOTAL.labels(
route=route,
backend=backend,
endpoint=endpoint,
model=model,
tier=str(tier),
status=status
).inc()
def record_latencies(
backend: str,
endpoint: str,
model: str,
ttft_ms: float | None,
itl_ms: float | None,
tpot_ms: float | None,
total_ms: float
) -> None:
"""Record all latency metrics for a request."""
labels = {"backend": backend, "endpoint": endpoint, "model": model}
if ttft_ms is not None:
TTFT_SECONDS.labels(**labels).observe(ttft_ms / 1000)
if itl_ms is not None:
ITL_SECONDS.labels(**labels).observe(itl_ms / 1000)
if tpot_ms is not None:
TPOT_SECONDS.labels(**labels).observe(tpot_ms / 1000)
INFERENCE_LATENCY_SECONDS.labels(**labels).observe(total_ms / 1000)
def record_shadow_result(
status: str,
tier: int,
similarity_score: float | None = None,
latency_diff_ms: float | None = None,
cost_savings_usd: float | None = None,
is_quality_match: bool = False,
) -> None:
"""Record shadow mode comparison results."""
SHADOW_REQUESTS_TOTAL.labels(status=status).inc()
if status == "success":
if similarity_score is not None:
SHADOW_SIMILARITY_SCORE.observe(similarity_score)
if is_quality_match:
SHADOW_QUALITY_MATCH.labels(tier=str(tier)).inc()
Traces: OpenTelemetry to Tempo
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
def setup_tracing(
service_name: str = "inference-sentinel",
otlp_endpoint: str | None = None,
) -> None:
"""Initialize OpenTelemetry tracing."""
resource = Resource.create({
SERVICE_NAME: service_name,
"service.namespace": "inference-sentinel",
})
provider = TracerProvider(resource=resource)
# Export to Tempo via OTLP
if otlp_endpoint:
otlp_exporter = OTLPSpanExporter(endpoint=otlp_endpoint, insecure=True)
provider.add_span_processor(BatchSpanProcessor(otlp_exporter))
trace.set_tracer_provider(provider)
# Context manager for spans
@contextmanager
def trace_span(
name: str,
attributes: dict[str, Any] | None = None
) -> Generator[Span, None, None]:
"""Create a traced span context."""
tracer = get_tracer()
with tracer.start_as_current_span(name) as span:
if attributes:
for key, value in attributes.items():
if value is not None:
span.set_attribute(key, value)
yield span
# Decorator for easy function tracing
def traced(name: str | None = None):
"""Decorator to trace a function."""
def decorator(func):
span_name = name or func.__name__
async def async_wrapper(*args, **kwargs):
with trace_span(span_name) as span:
try:
result = await func(*args, **kwargs)
span.set_status(Status(StatusCode.OK))
return result
except Exception as e:
span.set_status(Status(StatusCode.ERROR, str(e)))
span.record_exception(e)
raise
# ... sync wrapper similar
return async_wrapper if asyncio.iscoroutinefunction(func) else sync_wrapper
return decorator
Logs: Structured with structlog
import structlog
def setup_logging(
log_level: str = "INFO",
json_logs: bool = True, # JSON for Loki, console for dev
) -> None:
"""Configure structured logging."""
processors = [
structlog.stdlib.add_logger_name,
add_log_level,
add_timestamp,
structlog.processors.StackInfoRenderer(),
structlog.processors.format_exc_info,
]
if json_logs:
processors.append(structlog.processors.JSONRenderer())
else:
processors.append(structlog.dev.ConsoleRenderer(colors=True))
structlog.configure(
processors=processors,
wrapper_class=structlog.stdlib.BoundLogger,
logger_factory=structlog.stdlib.LoggerFactory(),
)
Helper Logger Classes
Domain-specific loggers for cleaner call sites:
class InferenceLogger:
"""Helper for logging inference-related events."""
def __init__(self, logger_name: str = "sentinel.inference"):
self.logger = get_logger(logger_name)
def request_started(
self,
request_id: str,
route: str,
backend: str,
tier: int,
tier_label: str,
entities: list[str]
) -> None:
"""Log when an inference request starts."""
self.logger.info(
"Inference request started",
request_id=request_id,
route=route,
backend=backend,
privacy_tier=tier,
privacy_tier_label=tier_label,
entities_detected=entities
)
def request_completed(
self,
request_id: str,
backend: str,
model: str,
total_tokens: int,
latency_ms: float,
cost_usd: float,
) -> None:
"""Log when an inference request completes."""
self.logger.info(
"Inference request completed",
request_id=request_id,
backend=backend,
model=model,
total_tokens=total_tokens,
latency_ms=round(latency_ms, 2),
cost_usd=round(cost_usd, 6),
)
class ClassificationLogger:
"""Helper for logging classification events."""
def sensitive_content_detected(
self,
tier: int,
tier_label: str,
entities: list[dict]
) -> None:
"""Log when sensitive content is detected (tier >= 2)."""
if tier >= 2:
# Don't log the actual content, just metadata
self.logger.warning(
"Sensitive content detected",
privacy_tier=tier,
privacy_tier_label=tier_label,
entity_types=[e.get("entity_type") for e in entities],
action="routing_to_local"
)
The Grafana Dashboards
Two dashboards provide operational visibility:
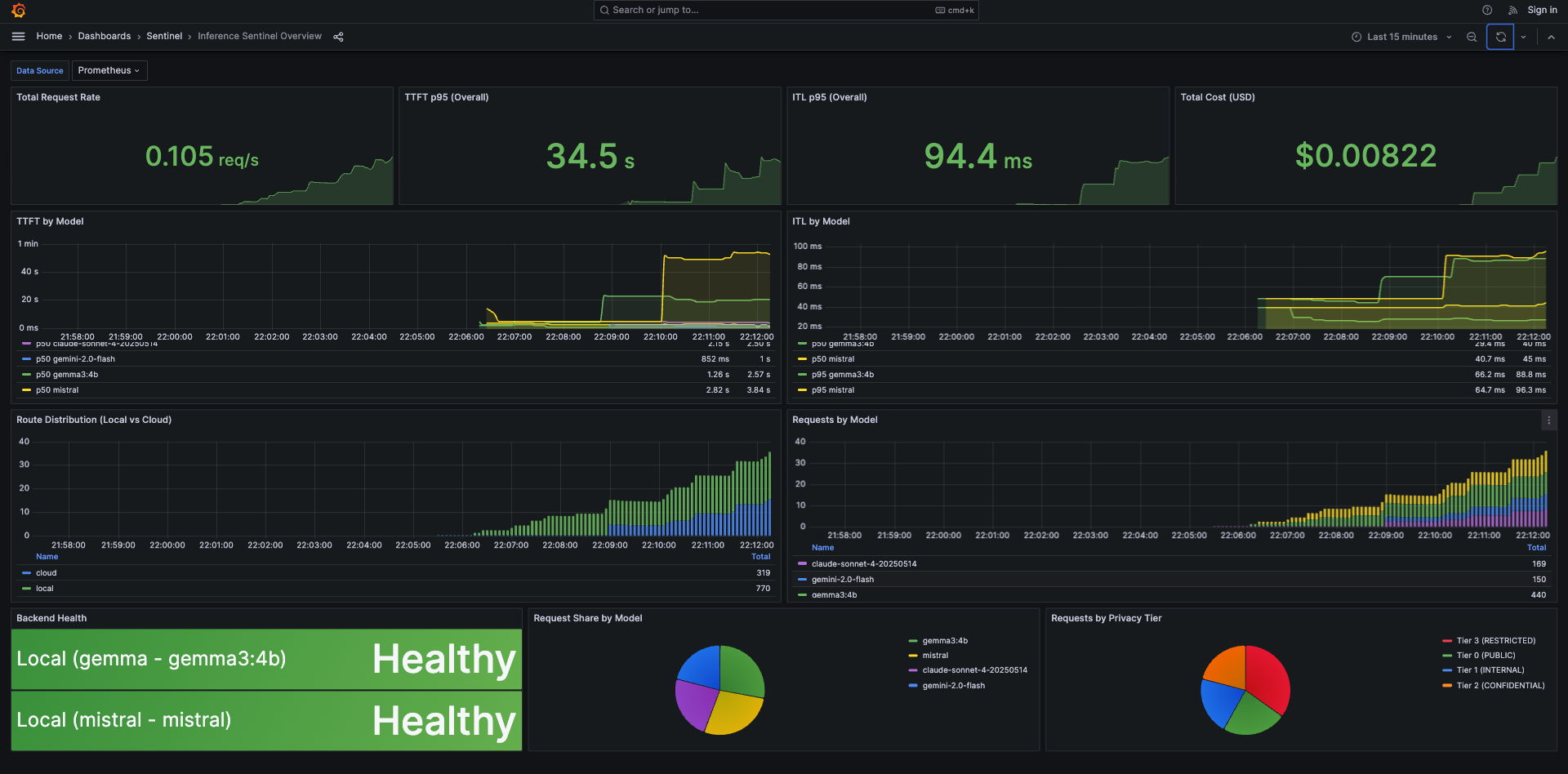 Real-time monitoring: request rate, TTFT/ITL by model, route distribution, backend health, and cost tracking
Real-time monitoring: request rate, TTFT/ITL by model, route distribution, backend health, and cost tracking
Operational health
- Backend Health: gemma and mistral both healthy
- Route Distribution: 70% local, 30% cloud
- Request Share by Model: Traffic distribution across all backends
- Per-model TTFT, ITL, and TPOT
- Cost accumulation
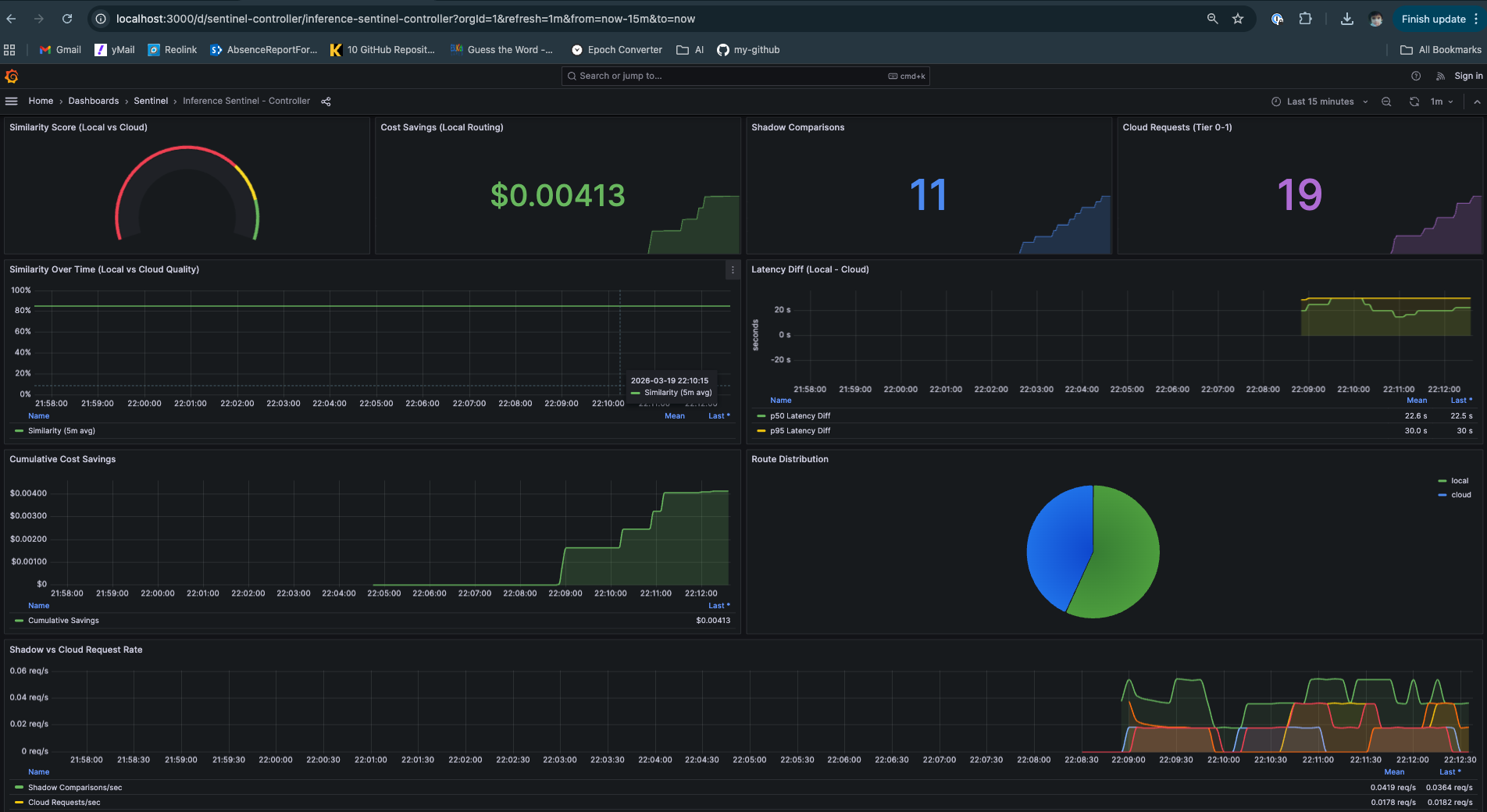 Controller Decisions Data: Similarity Score, Shadow Comparison, Cost Savings and Routing Recommendations
Controller Decisions Data: Similarity Score, Shadow Comparison, Cost Savings and Routing Recommendations
Controller Dashboard — ML/quality metrics
- Similarity score trends
- Shadow comparison counts
- Latency differential (local - cloud)
- Cost savings over time
- Routing recommendations log
Design Decision: Metric Cardinality
Trade-off considered: More labels = more granular data, but also more time series (cardinality explosion).
My approach:
route: 2 values (local, cloud)backend: 4 values (ollama, anthropic, google, unknown)endpoint: ~4 values (gemma, mistral, anthropic, google)model: ~6 values (bounded by configured models)tier: 4 values (0, 1, 2, 3)status: 2 values (success, error)
Total theoretical cardinality: 2 × 4 × 4 × 6 × 4 × 2 = 1,536 series. Acceptable for a single-instance deployment.
Lesson learned: I added the model label to REQUESTS_TOTAL late, which broke existing Grafana queries. Design your metrics schema before writing dashboards.
Deployment Architecture
Docker Compose Stack
services:
sentinel: # The gateway (FastAPI)
prometheus: # Metrics storage
grafana: # Visualization
loki: # Log aggregation
tempo: # Distributed tracing
# Optional - only with --profile containerized
ollama: # Local inference (if no native Ollama)
Default setup: Ollama runs natively on the Mac Mini M4 to leverage Metal GPU acceleration. The gateway connects via host.docker.internal:11434.
Containerized option: For environments without native Ollama, run with the profile flag:
docker-compose --profile containerized up -d
This pulls and runs ollama/ollama:latest with gemma3:4b and mistral pre-loaded.
Design Decision: Why Not Kubernetes?
Trade-off considered:
| Deployment | Pros | Cons |
|---|---|---|
| Docker Compose | Simple, local-friendly | Single node only |
| Kubernetes | Scalable, production-grade | Complexity overhead |
My choice: Docker Compose for v1.
Reasoning:
- Primary use case is local inference on a single Mac Mini M4
- K8s manifests are planned for Phase 6
- Compose is sufficient to demonstrate the architecture
- Lower barrier to entry for people trying the project
Configuration Philosophy
Environment Variables vs .env File
I use pydantic-settings which supports both:
class Settings(BaseSettings):
model_config = SettingsConfigDict(
env_prefix="SENTINEL_",
env_nested_delimiter="__",
env_file=".env",
env_file_encoding="utf-8",
extra="ignore",
)
# Nested config classes
local: LocalBackendsConfig
cloud: CloudBackendsConfig
cloud_selection: CloudSelectionConfig
session: SessionConfig
shadow: ShadowConfig
controller: ControllerSettings
telemetry: TelemetryConfig
Priority order:
- Environment variables (highest)
.envfile- Default values (lowest)
Lesson learned: This caused a subtle bug. SENTINEL_LOCAL__SELECTION_STRATEGY=priority in my shell was overriding selection_strategy: round_robin that I expected from defaults. The nested delimiter __ is powerful but can be surprising.
Semantic Validation with Pydantic
After getting bitten by invalid config values, I added range constraints:
class SessionConfig(BaseSettings):
lock_threshold_tier: int = Field(
default=2,
ge=1, # Must be >= 1
le=3, # Must be <= 3
description="Minimum tier to trigger LOCAL_LOCKED"
)
ttl_seconds: int = Field(
default=900,
ge=60, # At least 1 minute
le=86400, # At most 1 day
)
This prevents lock_threshold_tier: 5 from being accepted — pydantic will raise a validation error at startup.
What I’d Do Differently
1. Start with Structured Logging
I added structlog late. Retrofitting structured logging is painful. Start with it from day one.
2. Integration Tests Earlier
Unit tests are great but don’t catch issues like “the regex works but the NER model isn’t loaded in Docker.” Integration tests against a real Ollama instance would have caught several bugs earlier.
3. Add Semantic Validators Early
I initially relied on pydantic’s type validation alone. After deploying with an invalid lock_threshold_tier: 5, I learned to add ge=/le= constraints from the start. Now invalid configs fail fast at startup.
4. Metrics Design Up Front
I added the model label to REQUESTS_TOTAL late, which broke existing Grafana queries. Design your metrics schema before writing dashboards.
Coming Up: Part 2
In Part 2, I’ll share the benchmarking results:
- Classification accuracy across 1000+ test cases
- Latency percentiles (TTFT, ITL, TPOT) by model
- Shadow mode similarity distributions
- Cost analysis: cloud vs local routing
- Controller recommendation accuracy
GitHub: github.com/kraghavan/inference-sentinel
Questions or feedback? Connect with me on LinkedIn.